阿里巴巴官宣史上最大规模开源发布,Qwen2.5 系列模型性能测试结果揭晓
![]() AI工具集
·
浏览 142 ·
点赞 0 ·
评论 0 ·
2个月前 (09-24)
AI工具集
·
浏览 142 ·
点赞 0 ·
评论 0 ·
2个月前 (09-24)
一早,阿里来个大动作,历史性开源发布了!三款新模型亮相,有基础版Qwen2.5,编程专用Qwen2.5-Coder,还有数学专用Qwen2.5-Math。这几个模型有好几个版本,像0.5B、1.5B这样,加起来一共7个。不管是个人还是公司,手机电脑都能用。这技术上一大跃进,对开源界也是一大贡献。你们看看,这么个小家伙测试中都能干翻大块头,简直科技界开了挂似的!
这次阿里出的Qwen2.5-72B模型在MMLU-Pro测试里表现超棒。别小看它只有720亿参数,几个项目里都打败了Meta的Llama-3.1,参数多了一倍多。跟Mistral的Large-V2比也不差,现在可以说是最强的开源模型之一了。连没指令的版本都比Llama-3-405B强。加了指令后,它甚至比谷歌的Gemma2-27B和微软的Phi-3.5-MoE-Instruct都厉害,只在三项测试里稍微弱了点,其他地方都是赢的。这不仅仅是个小胜利,更是对小参数模型潜力的强力认可。

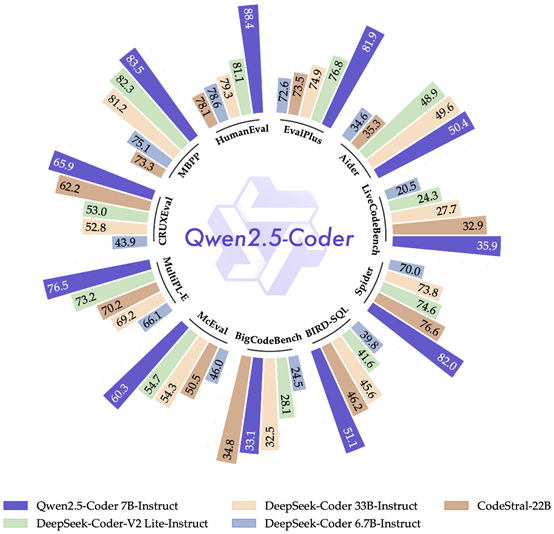
Qwen2.5-Coder-7B指令微调版本,编程新利器
自从阿里推出了CodeQwen1.5,大家伙儿都用它解决了不少编程难题,像修BUG、找问题点、给代码提点建议啥的。这次出的Qwen2.5-Coder-7B,性能测试里简直把那些参数多、响当当的模型给比下去了。它参数不多,但编程能力那叫一个强。谁承想这么个小巧的7B模型,编程水平这么硬核,简直就是开发者的救星!
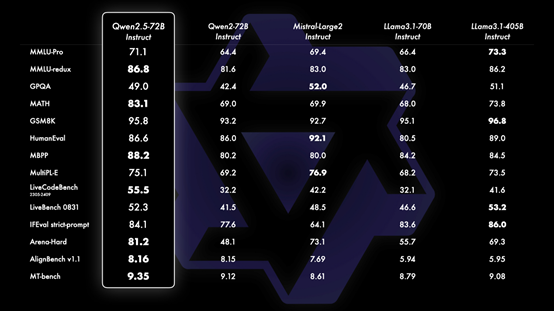
Qwen2.5-Coder-7B一出,整个编程界都沸腾了。这玩意儿让问题解决变得超轻松,还时不常给你一些高招。新手简直像开了外挂,老司机用起来也感觉手到擒来。这小玩意儿效率忒高,既不费资源,又提速明显。
Qwen2.5-Math-72B,数学领域的突破
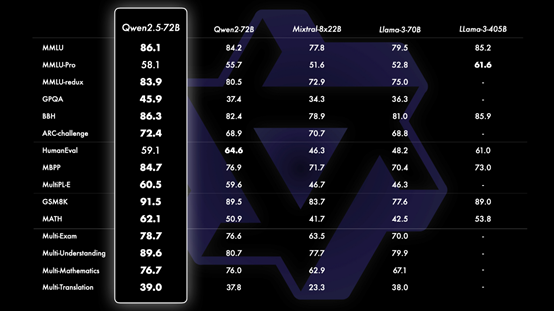
阿里最近推出了个数学新宝——Qwen2.5-Math。这个宝贝在超多、超好的数学资料库里头磨炼过,还用Qwen2-Math造的假数据练手。我发现,这Qwen2.5-Math-72B比以前的模型厉害多了,连GPT4-o那个闭源的啥啥啥都比不上。这不仅让模型进步了大,也给数学界来了个超级助攻!
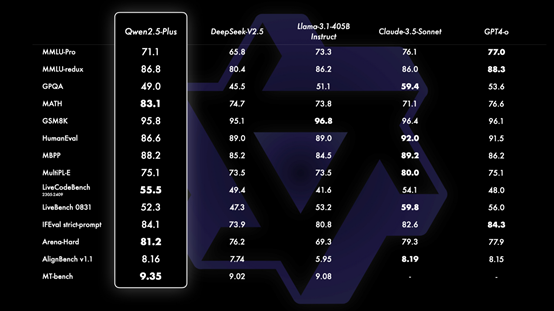
这Qwen2.5-Math-72B终于来了,数学研究者们有福了!它解起题来很牛,数据也做得超酷。对咱们数学人来说,简直就是救星。在教育界,这东西也让老师轻松,学生学数学更容易。这个小巧能干的家伙,省电又提速研究。
小参数大能量,Qwen2.5系列的惊人表现
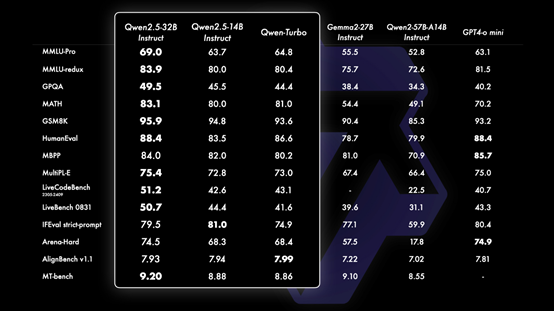
看这些测试数据,哪怕是参数不多的模型,只要数据够好、架构强,也能打败参数多的模型,这在节能和部署上很有优势。阿里最近推出的Qwen2.5系列,把小参数模型的性能推到了顶。跟Qwen-2比,Qwen2.5用的预训练数据直接飙到18万亿个tokens,比Meta刚出的Llama-3.1还多,现在是开源模型中的数据霸主。
Qwen2.5在这些事儿上挺溜的,比如拉长话题、搞表格、出JSON,真厉害。所以表现上去了,能干的东西也多起来了。才720亿参数就做到顶尖,真是太神奇了,像科技界的强者一样!
结语:小参数模型的未来,你准备好了吗?
阿里这次推出的Qwen2.5系列,简直是突破性的大进步,对开源圈太重要了。就像我们常用的那一小撮模型,技术上缩水了,居然还能打败那些庞然大物。不光省电,对地球也是有利的。咱们都得赶这个时髦,你觉得?你已经准备好接受小模型技术挑战,迎接这个新时代了吗?
内容来自网络,如有侵权,联系删除。

猜你喜欢



发表评论
电子邮件地址不会被公开。 必填项已用*标注
