腾讯开源超大模型 Hunyuan-Large,超越 Meta 最新模型并提升性能
![]() AI工具集
·
浏览 38 ·
点赞 0 ·
评论 0 ·
2周前 (11-08)
AI工具集
·
浏览 38 ·
点赞 0 ·
评论 0 ·
2周前 (11-08)
在人工智能的今天,各式各样的模型层出不穷。其中,Hunyuan-Large模型以其卓越性能独树一帜。腾讯的公开测试数据表明,它的性能超越了Meta开源的模型,即便在参数较少的情况下,性能也提升了3.2%。这无疑是一大亮点,也激发了我们深入挖掘其背后奥秘的欲望。
合理的专家激活机制
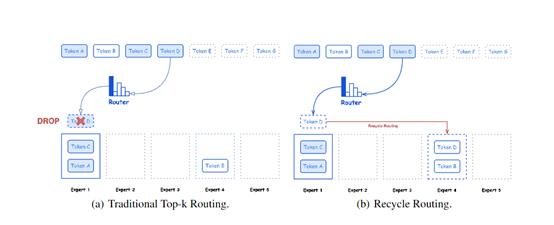
在模型训练阶段,并非所有专家都会被同时启用,这是Hunyuan-Large模型的一项精妙设计。以一个项目为例,若涉及50位专家,按常规做法或许会全部激活,但该模型仅会激活其中的一部分。它会将token重新分配给那些容量未满的专家。这就像在团队中分配任务,若平均分配给每位成员,效率必然不高。相反,若合理分配给部分成员,工作就能高效推进。如此一来,不仅能在时间上大幅节省训练所需的时间,而且在空间上也不需要过多资源来支持同时激活。在不同的任务阶段或面对不同的数据输入时,模型能灵活调整激活专家的数量,确保效率达到最高。
这种机制在提升模型稳定性方面也有所体现。众所周知,某些模型在训练阶段可能会因处理过多专家数据等多重因素而变得不稳定。比如,有一个类似的项目,起初启动了众多专家,结果模型频繁崩溃。然而,Hunyuan-Large却成功避免了这一问题,它有条不紊地完成了训练过程。
高效的KV缓存压缩技术
在传统的Transformer架构里,每一层都需要存储之前计算出的键值对,这对于处理长序列信息至关重要。Hunyuan-Large的KV缓存压缩技术,就好比是对这种存储进行了一次精细的“瘦身”。曾经有过一个测试,面对数千字符的长文本序列输入,普通模型因为内存占用过高而直接崩溃。但Hunyuan-Large应用了这项技术后,不仅保持了模型处理长序列的能力,还减少了存储空间。这样一来,它不仅降低了内存的使用,而且在保证准确性和速度不受影响的情况下,使得模型即便在内存受限的设备上也能高效运行。
它巧妙地保证了处理长文本的能力不受影响,同时减少了存储空间。这样一来,即便是在配置较低的硬件平台上,它也能顺畅运行,极大地拓宽了其应用范围。例如,在旧款服务器或个人电脑上,也能部署并运行此模型,无需高端昂贵的硬件,即可完成复杂的长文本处理工作。
灵活的专家特定学习率缩放
Hunyuan-Large模型选用AdamW作为优化器,并会根据批量大小来调整学习率。举个例子,在处理大量数据时,若所有专家使用相同的学习率,可能会出现有的专家参数调整过激,有的则调整不足。为此,该模型会根据每位专家处理token的数量来分配不同的学习率。假设有10位专家,过去可能都采用相同的学习率进行优化,而现在则会根据每位专家的实际工作负荷量来分配学习率。
这一措施在提升训练效率上表现出色。与一些类似模型相比,未采用这种学习率分配的模型,需要更多的迭代来达到相似的优化效果。然而,Hunyuan-Large模型能更快地收敛至更优结果,不仅节省了训练时间,还在模型精度上有所提高。
海量且高质量的训练数据
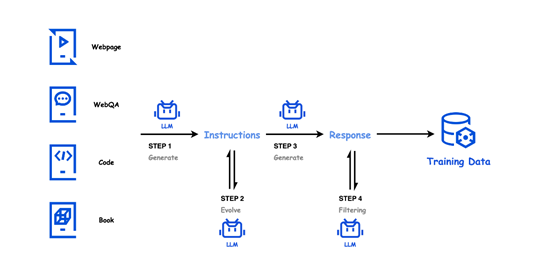
Hunyuan-Large项目共利用了七万亿token进行数据预训练,其中约一亿五千万token为高质量且多样化的合成数据。这相当于为模型搭建了一个庞大而丰富的知识库。若将模型比作一个人,那么这些数据便是其成长过程中所需的各种知识滋养。它涵盖了从网页内容到问答数据,从代码库知识到书籍信息等众多类型的数据来源。试想,若模型仅从书本知识中获取信息,它对外界新兴网络内容的理解便会存在不足。而Hunyuan-Large通过全面的数据源采集,使其在应对各类实际问题时的表现更加得心应手。
大量数据固然重要,但更需注重其质量。以指令生成环节为例,优质的数据来源至关重要,它和各类指令生成提示相辅相成,共同孕育出覆盖多个领域的指令。这就像一位大厨烹饪佳肴,优质的食材是根本,而烹饪手法(指令提示)则直接决定了最终成品的品质。
渐进式的指令优化流程
Hunyun-Large在指令生成、演化、响应生成和过滤这四个阶段持续优化指令,这一流程对于提升其性能至关重要。在指令生成阶段,它利用多种优质数据源来生成多样化的指令。进入指令演化阶段,就像是对一个初步方案进行细化和升级,增强了指令的清晰度和信息量。比如,一家公司的策划案在初始完成后,还需对细节进行改进。随后进入响应生成阶段,多个专业化的模型为指令提供精确的答案。最后在过滤阶段,它将去除低质量的内容,确保整体质量。
渐进式流程对模型探索解空间大有裨益。这就像在迷宫中寻找出口,若随意乱闯,很快就会陷入局部最优的困境。但若按照既定阶段逐步调整,就如同有了明确的路线,就不会过早地陷入次优结果。
长文本预训练强化能力
模型在完成退火阶段后,会进行长文本的预训练,token长度也从最初的32K逐步增加至256K。这样的做法显著提升了模型处理长文本的能力。面对如超长科研论文或长篇小说等文档内容,未经长文本预训练的模型可能会在处理时出现混乱,难以准确把握全文含义和提取关键信息。然而,Hunyuan-Large凭借这种长文本预训练,能够自如地应对长文本内容。无论是文档分析还是摘要生成等长文本相关任务,它都能轻松应对。
在处理长文本时,你是否曾感到模型显得有些力不从心?欢迎各位在评论区留下你的经历和看法。同时,也希望你能为这篇文章点赞和转发,让更多的人认识到Hunyuan-Large模型的优势所在。
内容来自网络,如有侵权,联系删除。

猜你喜欢
发表评论
电子邮件地址不会被公开。 必填项已用*标注
