OpenAI o1 模型推出后,大型语言模型推理能力引发热议
![]() AI工具集
·
浏览 349 ·
点赞 0 ·
评论 0 ·
5个月前 (10-23)
AI工具集
·
浏览 349 ·
点赞 0 ·
评论 0 ·
5个月前 (10-23)
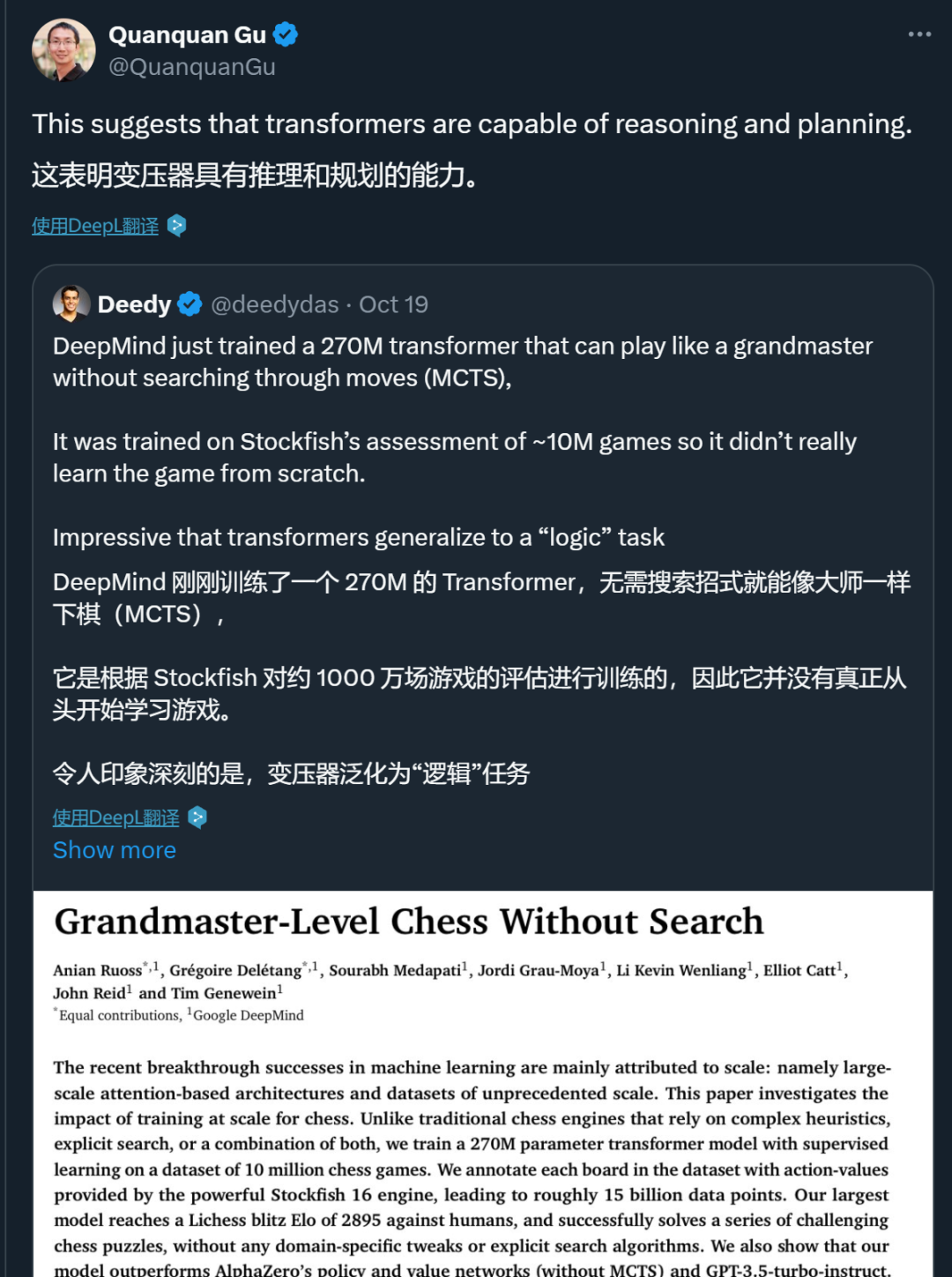
OpenAI推出的o1模型引起了广泛关注,特别是其大型语言模型的推理能力。在国际象棋领域,研究者们对如何通过监督学习制定具有广泛适用性的策略既感到兴奋又感到困惑。这一成果预示着人工智能技术的重大进展,也关系到对模型推理能力的新评价标准。

明确研究的背景意义
在人工智能迅猛发展的今天,大型语言模型的推理能力评估成为了关注的焦点。OpenAI的o1模型问世后,这个问题的研究显得尤为重要。在国际象棋领域,以往的成功策略往往依赖于复杂的算法推理和启发式规则。而在其他领域,模型通过监督训练等方法取得了显著成效。是否能在国际象棋领域行得通,成为了关键性的出发点,它将决定未来人工智能下棋技术的发展方向。比如,深蓝在击败国际象棋大师时,主要依靠算法的优化计算。这代表了早期人工智能下棋的技术趋势。
国际象棋,作为棋类项目的典型,其复杂性与逻辑性让它始终是人工智能研究的焦点。随着机器学习方法的兴起,研究国际象棋的策略正迎来新的思路。将新技术引入国际象棋,有望揭示通用人工智能的发展路径,为打造更智能的人工智能系统提供借鉴。
传统国际象棋策略相关技术
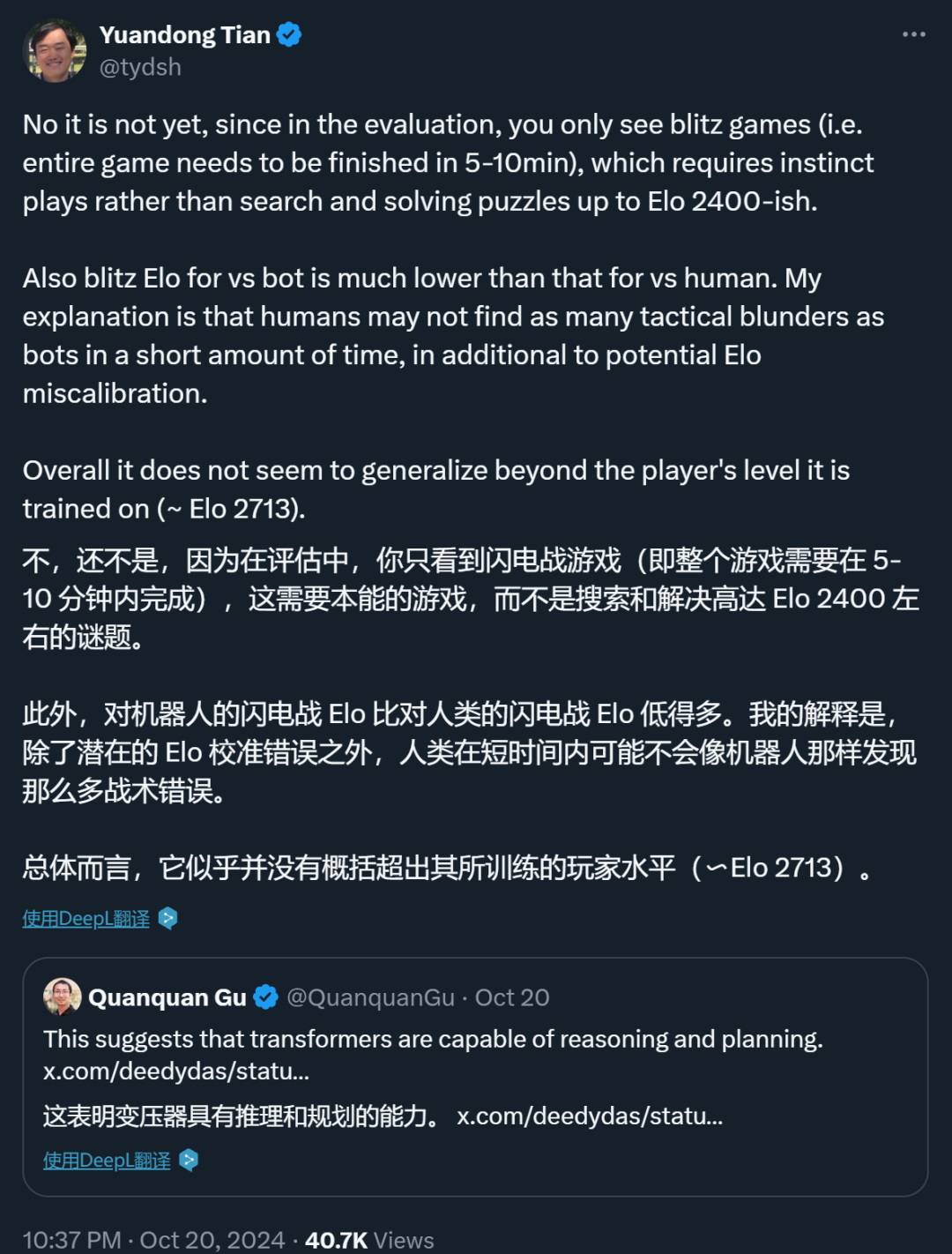
传统策略中,搜索组件扮演着关键角色,是多数高级别计算机象棋系统的必备。然而,DeepMind的AlphaZero与LeelaChessZero却有着不同之处,它们依赖搜索与自学的启发式规则,而非依赖人类的象棋知识。比如,AlphaZero在自学过程中,通过自我探索,深入挖掘众多棋局特征,并发现了关键的步骤。

国际象棋的高效策略往往包含算法推理,比如搜索和动态规划等,以及启发式规则的应用。过去,许多人工智能的棋类系统在每一步棋时,都会进行搜索,并依赖预先设定的启发式规则来评估棋局的优劣。这些复杂的逻辑是传统国际象棋程序处理棋局和行棋的基础。
本研究的实验设计思路
更是从架构的使用角度切入,作者采用了基于注意力的标准架构,这种架构是众多先进人工智能模型普遍采用的。举例来说,在自然语言处理领域,它已经展现出了显著的效能。而在本研究中,将其应用于国际象棋,则是一种尝试性的移植。
监督训练协议是用于学习预测棋盘动作值的关键方法。通过利用过往棋局数据等信息进行监督学习,这一设置在实验中至关重要。例如,让模型根据先前棋局预测后续发展价值,这样的过程即是模型学习国际象棋策略的步骤之一。
预测器的设计与任务类型划分
在讨论预测器设计时,作者采用了仅含解码器的transformer作为核心结构。为了实现离散概率分布的参数化,他们还对transformer的输出施加了log-softmax层进行归一化处理。这就像为预测结果搭建了一个合理的分布框架,确保其输出的结果符合预期要求。
作者根据任务类型,将其分为动作-值预测、状态-值预测和行为克隆三种。这相当于对国际象棋局中各种分析视角和操作方法进行了分类。这些不同的任务类型在应对棋局时具有重要作用。例如,动作-值预测涉及对每一步棋的价值评估,而状态-值预测则能帮助整体把握棋局。

对比试验中的关键环节及结果
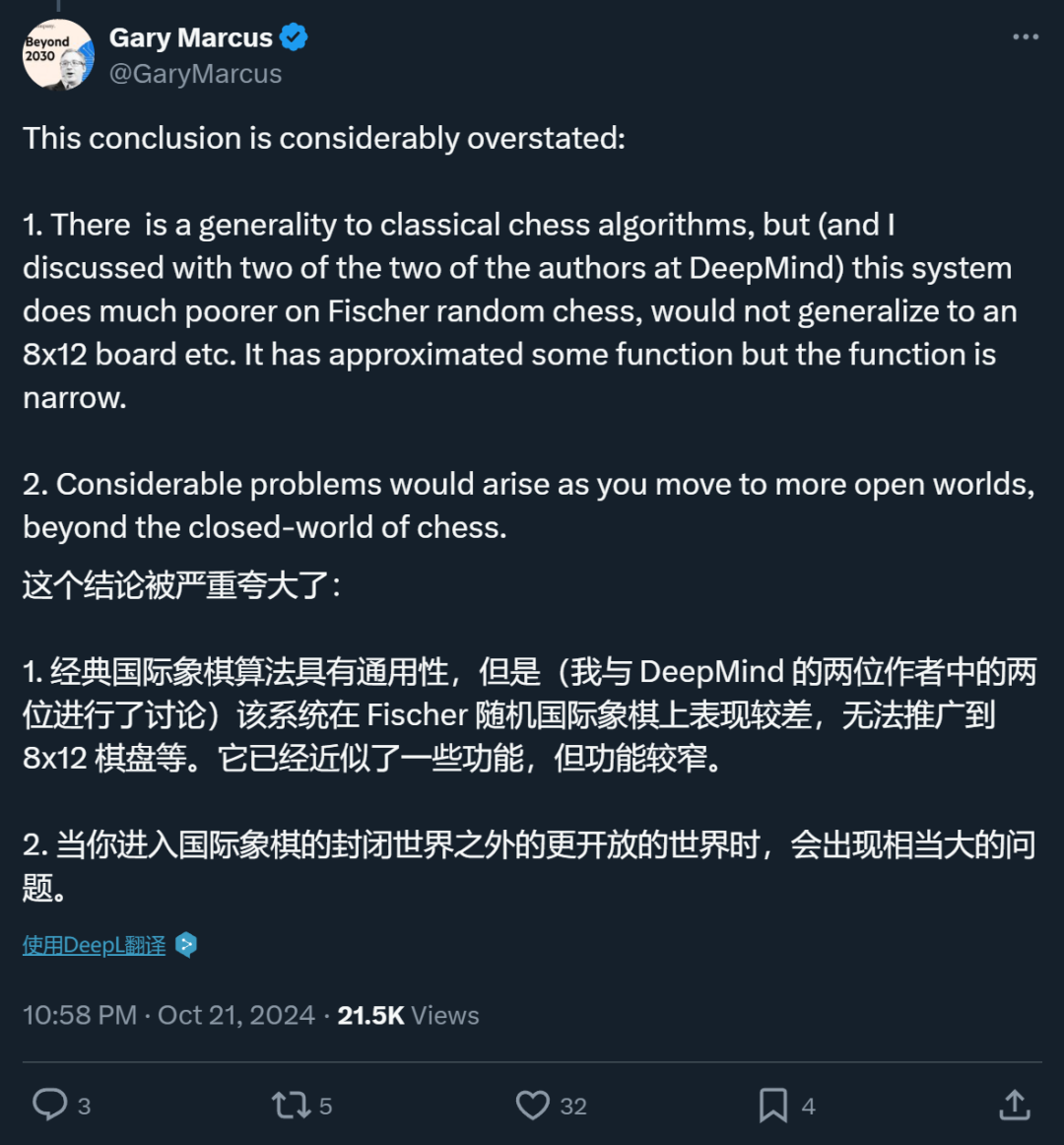
在对比环节,作者挑选了Stockfish16和AlphaZero的三个版本进行对比。GPT-4没有被纳入选择范围,主要原因是它在国际象棋中遇到了一些难以解决的难题,比如无法完整且合法地完成一局棋。在比较过程中,要求各种模型在相同的测试框架内进行棋局试玩和谜题处理。

实验结果显示,三个研究模型均表现出卓越的新棋盘泛化能力,成功破解了多数谜题。这体现了监督学习方式的独特魅力,尽管无法预先规划,但凭借值估计,仍能有效地应对。尤其在解决复杂谜题时,模型仍能提供合理的走法。
研究成果的价值与潜在影响
从积极的角度来看,这一成功发现为国际象棋策略研究打开了新的道路。未来,我们可以沿着这一方向对其他类似的人工智能下棋系统进行改进。比如,让其他模型学习这一价值评估的方法,以此来增强它们的对弈能力。
潜在问题确实存在,比如在缺乏明确规划的情况下,这种策略在现实中的高端国际象棋比赛中是否依然有效,这一点尚需深入研究和更多实践来验证。同时,这也引发了一个值得思考的问题:大家认为,这种监督学习策略能否成功应用于其他棋类游戏?欢迎各位留言交流,点赞并分享这篇文章。
内容来自网络,如有侵权,联系删除。

猜你喜欢


发表评论
电子邮件地址不会被公开。 必填项已用*标注
