AI 生成软件:根据用户需求和声线设置,自动合成音频,内置大量高人气角色声音模型
![]() AI工具集
·
浏览 35 ·
点赞 0 ·
评论 0 ·
2周前 (11-11)
AI工具集
·
浏览 35 ·
点赞 0 ·
评论 0 ·
2周前 (11-11)
AI语音合成器在众多行业中已得到广泛应用,然而,很多人对于如何充分利用其功能却一知半解。它不仅功能强大,而且操作简便,却未能被广大用户充分了解和掌握,这确实令人感到遗憾。
理解AI语音合成原理
AI语音合成技术已经相对成熟。这种技术的工作原理是,通过分析用户输入的文字,利用算法将文字转换成语音。比如,在文案转语音的需求中,它可以识别中文句子的断句和语调。根据数据,现在许多新媒体从业者经常使用这类工具制作音频,每周使用次数可达3到5次。对于普通用户来说,若要录制有声读物,AI语音合成技术也能根据语义提供恰当的语音语调。
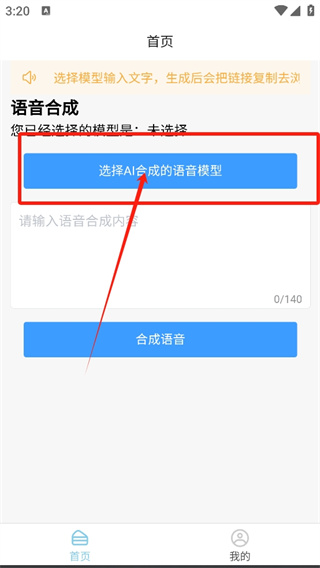
挑选合适的声音模型
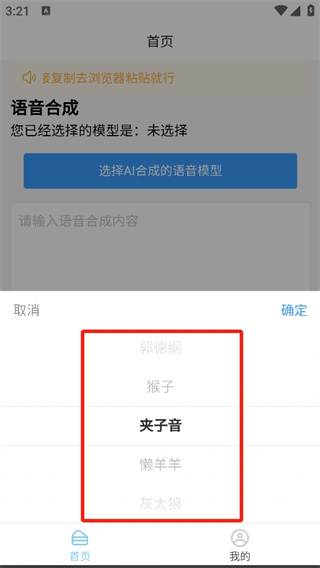
AI语音合成器的显著特点之一就是声音模型种类繁多。用户可以挑选各式各样的角色声音。比如,某些企业在做宣传时,就会选用雷军的声音模型,这样可以让宣传听起来既亲切又具有辨识度。若是要制作搞笑视频,郭德纲的声音模型或许是个不错的选择。此外,不同地区和人群有不同的喜好,比如年轻人可能更喜欢蔡徐坤这样的流行明星声音,而动漫爱好者则更偏爱赛马娘这样的动漫角色声音。
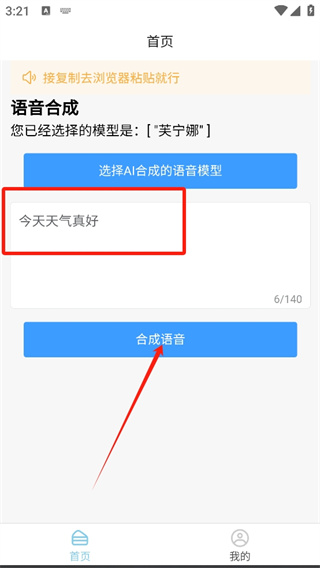
准确输入合成内容
在使用输入合成功能时,有几个小细节需要留意。若输入的是较长的文本,务必要保证其语义的流畅性。尤其是在制作商务报告的音频时,若内容逻辑不清晰,合成的语音听起来也会显得异常。同时,时间的把握也很关键。若音频需要在特定时间点播放,输入内容的时长也必须考虑在内。比如,若是为一场10分钟的路演制作音频,内容过多可能会导致音频超出预定时长,因此,对内容的长度要精确控制。
优化操作流程
操作流程虽不复杂,但仍存在改进的可能。打开软件挑选模型时,可依据过往使用习惯迅速找到所需。以常使用邓紫棋声音模型的用户为例,面对众多人物名称列表,只需输入“邓”字便可快速筛选。此外,在输入框输入内容时,预先进行编辑,能减少输入时的语法及拼写错误,确保语音生成的准确性不受影响。
处理生成后的音频
音频处理同样关键。若对音质感到不满,不妨尝试调整设备音频设置,以期提升音质。例如,在手机上,可以调整音量和均衡器等参数。在公共场所播放时,需根据场地规模调整音量大小。以容纳500人的礼堂为例,其音频响度应比小会议室的设置要高。此外,还需关注音频格式的兼容性,确保在其他设备上播放时,格式能得到识别。
探索更多隐藏功能
不能满足于基础功能。部分AI语音合成器具备语音变速功能,可根据需求迅速制作出慢速或快速语速的音频。在制作语言学习资料时,慢速音频尤为实用。此外,还有语音风格调整功能,能令语音听起来更加正式或生动。比如,制作儿童故事音频时,选用生动的语音风格更能吸引小朋友们的注意。
在使用AI语音合成器时,你是否曾遇到一些有趣的现象?不妨在评论区和大家分享一下。同时,也请大家给这篇文章点赞和转发。
内容来自网络,如有侵权,联系删除。

猜你喜欢



发表评论
电子邮件地址不会被公开。 必填项已用*标注
