深入解析真实标签与合成标签的不匹配及模型性能度量
![]() AI工具集
·
浏览 123 ·
点赞 0 ·
评论 0 ·
1个月前 (10-17)
AI工具集
·
浏览 123 ·
点赞 0 ·
评论 0 ·
1个月前 (10-17)
咱们在搞机器学习和数据科学这事儿的时候,训练模型那可真是得靠一大堆数据。可问题是,弄到那些质量好的真数据,成本高不说,还特耽误时间。所以,现在大家一般都拿合成数据来顶替。这篇文章就要聊聊怎么在训练模型的时候,把合成数据和真数据给巧妙地混搭起来,这样既能防止模型出问题,又能让模型的表现更上一层楼。
合成数据与真实数据的定义与区别
咱们说的合成数据,就是用算法弄出来的,一般用来补足那些真实数据不够用的地方。这种数据能模仿真实数据的分布情况,不过制作的时候可能会带进去一些乱七八糟的东西,比如噪声,偏差。而真实数据,就是从现实世界里收集来的,那可是货真价实的,可靠性高。在训练模型的时候,咱们会把这两种数据掺和在一起用,就是为了让数据既有量又有质,这样能提高模型推广到新情况的能力。
合成数据那玩意儿好在不花钱又能变大,可就是不够精细,有时候跟真数据差远了。真数据那质量是没得说,可要弄到手得花大价钱,还可能涉及到个人隐私和道德问题。所以说,咱们得巧妙地结合这两种数据,这样才能让模型的表现更上一层楼。
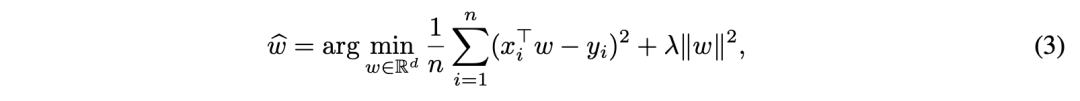
模型崩溃的原因分析
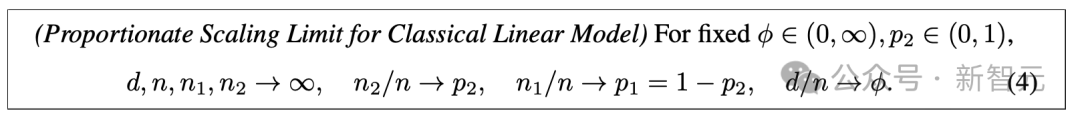
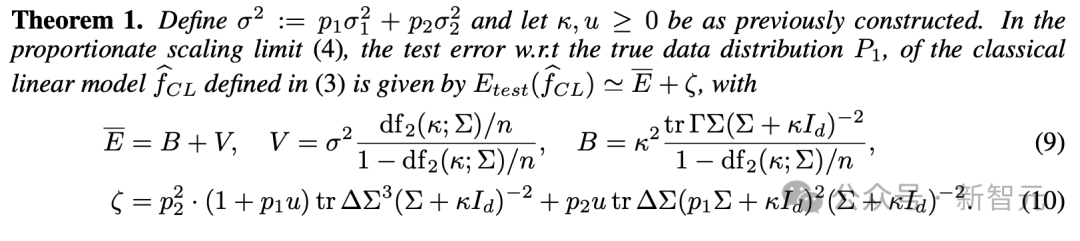
模型要是出了大问题,就是在训练的时候突然间表现不行了,学东西也不灵光了。这种情况多半是因为数据里头假的太多,可能还带点乱七八糟的东西,让模型学会了错误的知识,这样一来,它就不太会适应新情况了。再说了,那些假数据分布跟真数据不一样,模型在真数据面前就有点儿水土不服了。
要想不让模型出问题,咱们得把造出来的数据量给管住。据研究说,要是这些造出来的数据少得跟没一样,模型表现最稳。可光靠真数据,搞大训练量可能就不够用了。所以,怎么在保证模型稳如老狗的前提下,巧妙地用上这些造出来的数据,这可是个挺关键的学问问题。
ScalingLaw范式中的模型稳定性
这个ScalingLaw理论,主要是说模型的表现和数据处理量大小之间的关系。它说,模型是不是稳当,跟造出来的数据量大小关系挺大。定理1还有它那些结论,都说了,要是那些造出来的数据太多,模型就容易挂掉。所以,咱们得把那些数据量控制得小一点,这样才能保证模型不会出问题。

在实际操作里,咱们得一点一点地调整,把合成数据的份儿慢慢减下来,好让模型那扩大的能力回来。但就算这样,模型在某些地方还是可能要崩。这说明咱们得小心使合成数据,还得跟真数据掺和着来,好好调整调整。
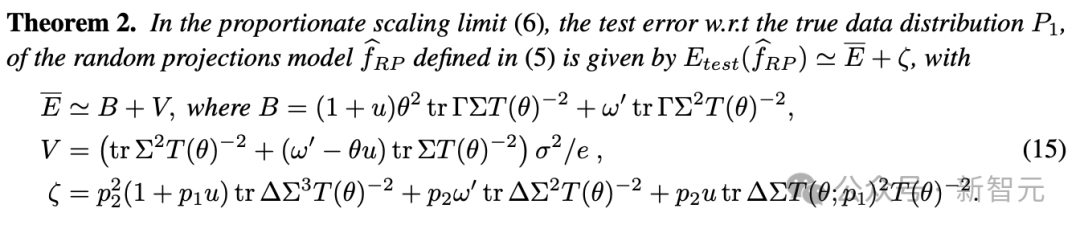
实验验证与理论预测的对比
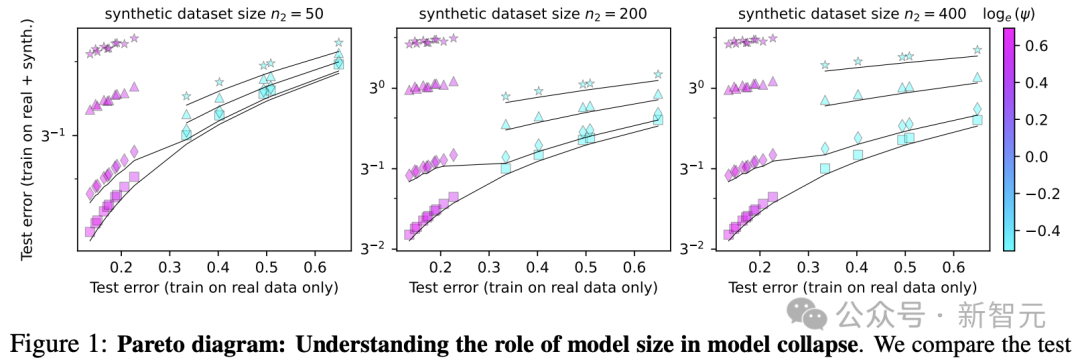
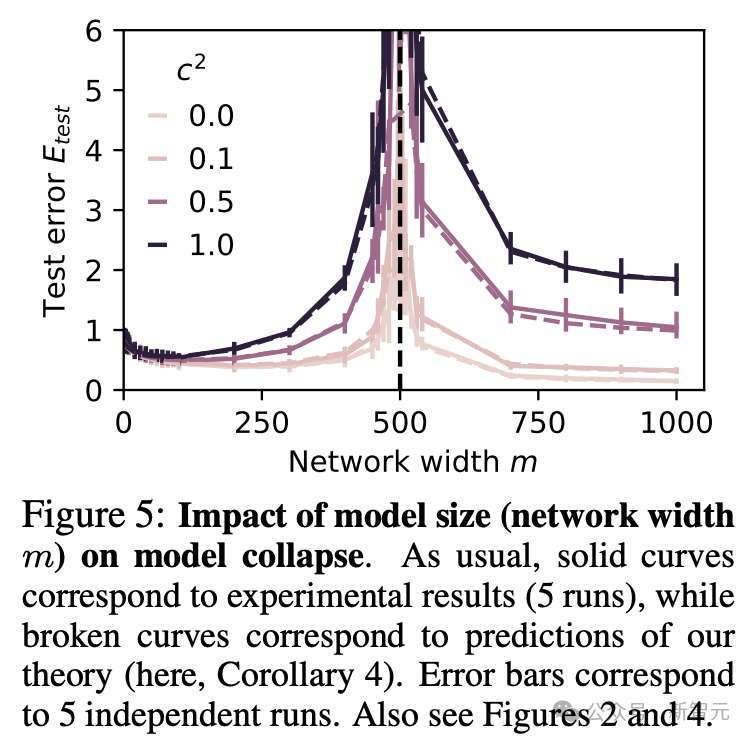
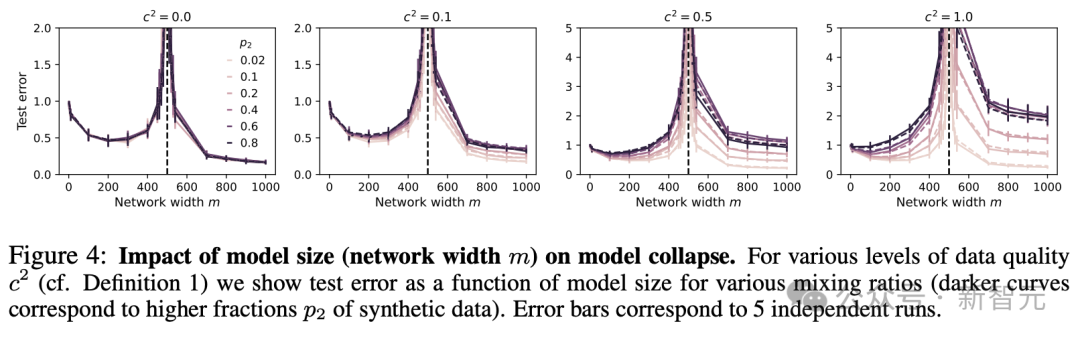
为了检验理论的准确性,研究团队开展了一系列实验。从图1和图5的实验结果来看,对于品质较高的合成数据来说,选用规模更大的模型(也就是更大的ψ值)确实是个不错的选择。而且,网络宽度m对模型的表现也有不小的作用,实验得到的曲线和理论预测值之间的吻合度相当不错。
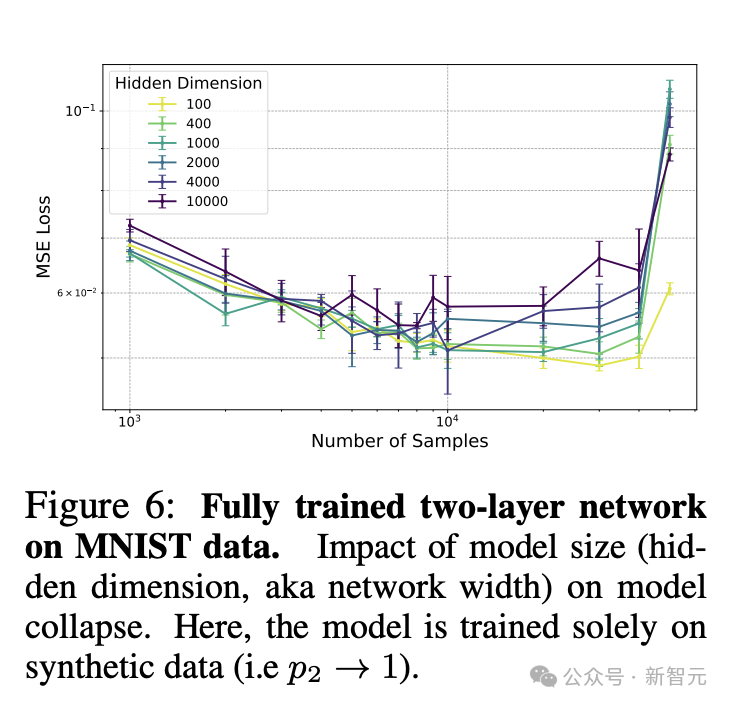
看图6和图7的实验结果,它们更加强调了之前的发现。就算我们用了经过全方位训练的双层网络,要是只用合成数据来训练,模型还是会出问题。这说明合成数据的品质和数量对模型的表现可是起着关键作用。
复杂情况下的模型训练
在实际操作中遇到各种复杂情况,比如用BabiStories数据集加上GPT2模型来操作,弄出那些假数据可就麻烦了。看图8那实验的成果,咱们发现就算是在复杂的环境里,也得小心翼翼地控制合成数据的量,不然模型可能就崩了。
为了探究真实数据和替代数据结合后的扩展定律,科研人员琢磨了各种提升策略。他们发现,经过一轮又一轮的混合迭代,到了t轮之后,就能得出跟E成正比的缩放比例。但即便如此,迭代混合虽然让缩放比例恢复到了一致,但模型还是多少有点失控。
迭代混合策略的局限性
迭代和混合这两种策略虽多少能抵消掉合成数据带来的影响,但这点不足还是得提防。研究显示,哪怕只是跟一点实际数据混搭着迭代,都有可能让模型直接挂掉。所以说,用合成数据的时候可得小心点,得跟真实数据一起优化,还得注意控制合成数据占的分量。
在实际操作里,用迭代和混合的方案可能达不到把模型缩放能力完全恢复的水平。所以,研究者们提议,咱们得把其他调优手段也给用上,比如数据增强还有模型规范化,这样子才能让模型的性能和稳当性都得到提高。
总结与展望
混搭着用合成和真数据是提高模型表现的关键招数,但得小心点用合成数据,别让模型给崩了。适当调整合成数据的分量,再跟真数据一起优化,就能大大增强模型的稳定性和适应各种情况的本事。
你觉得在练模型的时候,把假数据跟真数据掺一块儿用,可能会遇到啥子难题?来评论区说说你的想法,顺便给这篇文章点个赞,转发一下,让大伙儿都来关注这个关键问题。
内容来自网络,如有侵权,联系删除。

猜你喜欢



发表评论
电子邮件地址不会被公开。 必填项已用*标注
