AI 深度伪造技术引发关注,克隆声音门槛究竟有多低?
![]() AI工具集
·
浏览 98 ·
点赞 0 ·
评论 0 ·
1个月前 (10-17)
AI工具集
·
浏览 98 ·
点赞 0 ·
评论 0 ·
1个月前 (10-17)

现在咱们这技术挺发达,AI语音合成那玩意儿靠着各种资源快马加鞭地进步,可这同时也带来了个麻烦,就是有人能乱造声音。这事儿不光是配音啊、数字人这些行当受影响,连着内容传播、平台管理这些方方面面都得跟着出招儿应对。
AI语音合成素材来源的两面性
咱们从技术层面看,咱们的声音还有网上的声音资源都能当AI做语音合成的材料。这事儿一方面让配音还有数字人这些行当方便多了,成本也降了,效率也高了。就像那些小配音工作室,资源不咋多,也能做出各种配音效果来。可另一方面,声音来源这么多,也让AI做假声音变得容易了,坏人可能就利用这个来编造假消息。
咱们得注意,这AI语音合成技术,因为资料获取太容易了,所以发展环境挺复杂的。咱们得一方面鼓捣技术创新,让这行儿方便些,另一方面还得提防着那些潜在的风险。这玩意儿就像两面刃,用得对能创造价值,用不对就可能搞破坏。
开源软件与应用的标注与提示
在开源软件这块,作者对软件的界面标注是没得控制的,这事儿得使用者跟传播者自己来扛。所以说,虽然开源软件是敞开大门的,但责任归属是明明白白的。跟其他不少开源项目一样,这事儿也说明了咱们在分享技术成果的同时,还得自己管好自己。
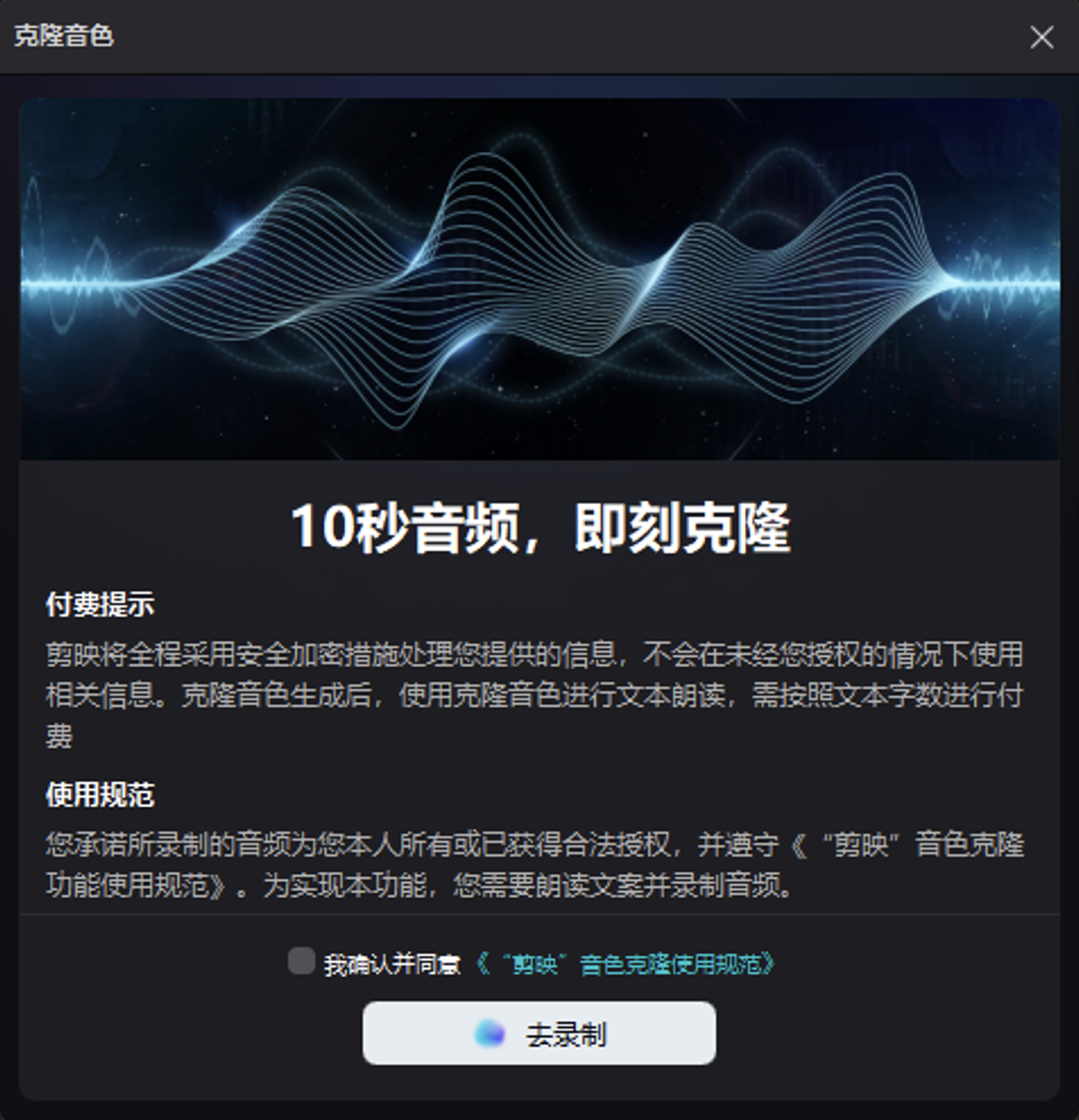
剪映这玩意儿出来个提醒,说信息得用加密手段来处理,咱得保证不让人随便乱用。这事儿既是给用户一个保障,也是企业对待AI语音合成材料得有个规矩。不过,就光这样还不够,咱们整个行业得在这方面多商量,达成更多共识。
平台对AI音频内容的识别困境
现在,那些AI做的声音简直跟真人似的,让那些平台都很难用啥有效方法来分辨这些内容。就像抖音啊、哔哩哔哩这些平台,虽然都有AI来提示内容是自动生成的,可检测起来还是挺有难度的。要是那些用AI做的音频创作者不标记,平台又检测不出来,那就有可能让假东西到处乱窜。
这平台的识别功能赶不上AI合成技术的飞速发展,一遇到海量的内容,想要准确判断就特别费劲。就像那些很小的音频片段,根本分不清是人说话的还是AI合成的,这事儿现在得赶紧给解决了。
国内外法律的相关规定与发展
好多国家跟咱们中国似的,都开始琢磨怎么给深度伪造这事儿立法了。咱们2022年那规定说,得把AI造出来的东西标记出来,不标记的说不定就得挨板子。不过,这法律还得往细里整。比如说,在分清哪些是合法的,哪些是侵权的时候,得考虑更多的具体情况。
往前看,咱们得把法律条文给细了,还得明确各方得保存好数据,弄个记录啥的。这样子,一旦出了啥事儿,咱们能准准地找到源头,还能把AI语音合成这事儿给整得规规矩矩的,从法律上头给这新玩意儿一个合理用法的保障。
技术层面的反伪造措施
咱们技术上得这么搞,就是在音视频里头塞个数字水印或者元数据啥的,这样一来,AI弄出来的东西就能追溯源头了。就像有些视频公司已经在他们作品里头试了这个法子。再就是,咱们得弄个更厉害的AI模型来检测那些深度伪造的玩意儿。这玩意儿在社交和新闻平台上作用可大了,能自动把那些假东西筛出来,保证信息的真材实料。
咱们这些技术招数,就是用来对付那些声音造假还有假信息乱传的,挺管用的。不过,技术这玩意儿得花时间投入,还得大家齐心协力才能往前推进。
平台的审核机制与公众举报机制
咱们这些大平台得弄个更狠的AI审核系统,比如上传东西的时候得用高科技反造假手段自动查查,尤其是那些跟名人啊敏感话题有关的,得特别小心。还得有个让大伙儿能痛快举报那些假东西的渠道,平台得赶紧反应,别让坏信息乱跑。
这个平台在AI语音合成内容的监管上担子可不轻。咱们得有套管用的审查办法,再跟大家伙儿的积极举报一起上,这样才能让网上这些内容更靠谱。
咱们用AI做语音合成,方便是挺方便的,可是一不留神也跟着冒风险,这俩玩意儿就像双刃剑似的,还在那儿斗来斗去的。你说,在这场较量里,最让人头疼的点啥是?快来聊聊你的看法,顺便也给这文章点个赞,转发一下。
内容来自网络,如有侵权,联系删除。

猜你喜欢

发表评论
电子邮件地址不会被公开。 必填项已用*标注
