OpenAI 下一代旗舰模型质量提升幅度不及前两款,Scaling Law 或无以为继
![]() AI工具集
·
浏览 187 ·
点赞 0 ·
评论 0 ·
4个月前 (11-14)
AI工具集
·
浏览 187 ·
点赞 0 ·
评论 0 ·
4个月前 (11-14)
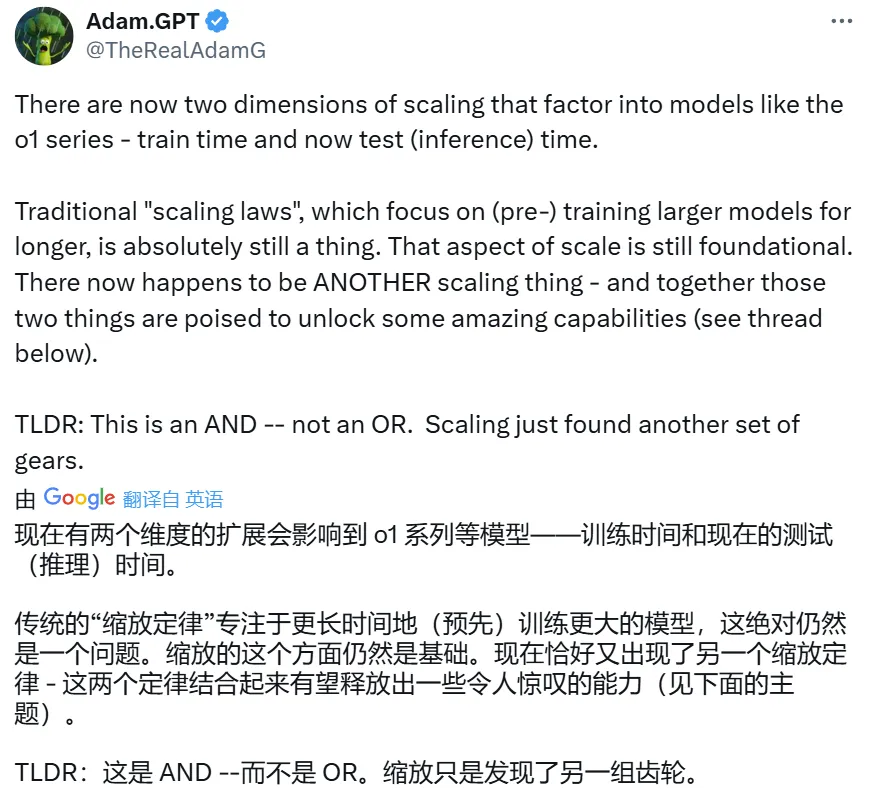
在人工智能模型发展的今天,模型性能的增强成为了众人关注的焦点。人们纷纷寻求提升模型表现力的有效途径。在众多方法中,测试时的计算手段备受瞩目,而测试时训练(TTT)技术的出现,更是引起了广泛关注。
理解测试时训练

测试时训练(TTT)与其它提升模型性能的方法有所区别。它依据测试时的输入,通过显式的梯度步骤来对模型进行更新。以特定语言模型(LM)为例,通常的做法可能是预训练或采样,而TTT则是在测试阶段介入,仿佛为模型在关键时刻补充新知识。在众多场景中,模型需要应对各种任务,比如在处理ARC语料库中的少次(few-shot)视觉推理问题时,模型需判断图形变换规则并得出输出结果,这时TTT便能发挥其作用。
此外,与其他传统预训练或推理阶段的方法不同,TTT主要在测试阶段进行操作。这对众多项目而言,是一种全新的尝试方向。只要掌握了它的操作理念,就能更有效地运用它。

TTT对模型性能的显著提升
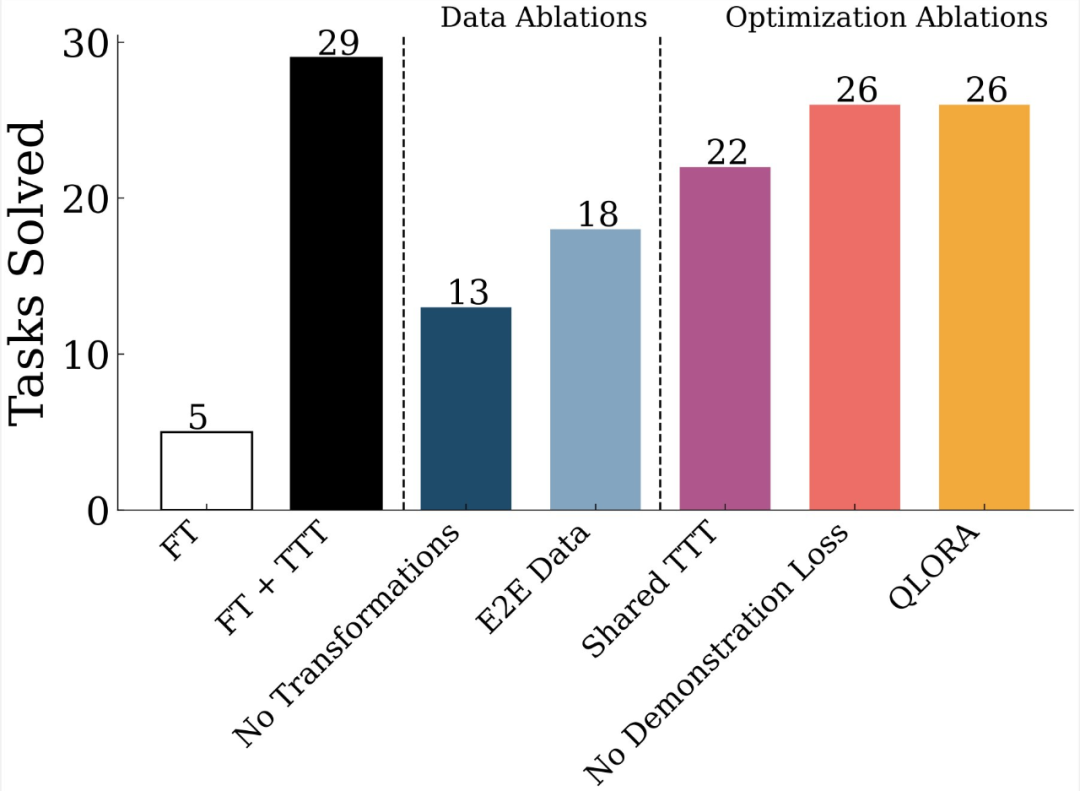
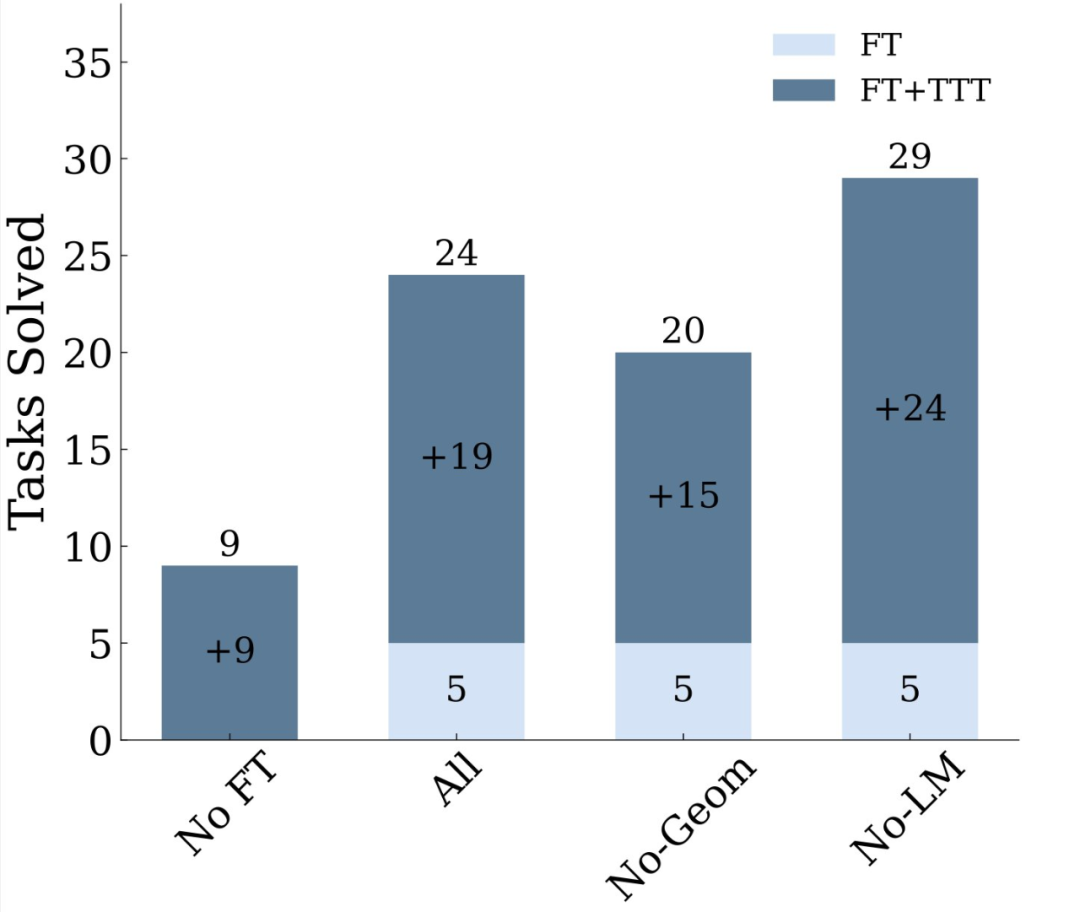
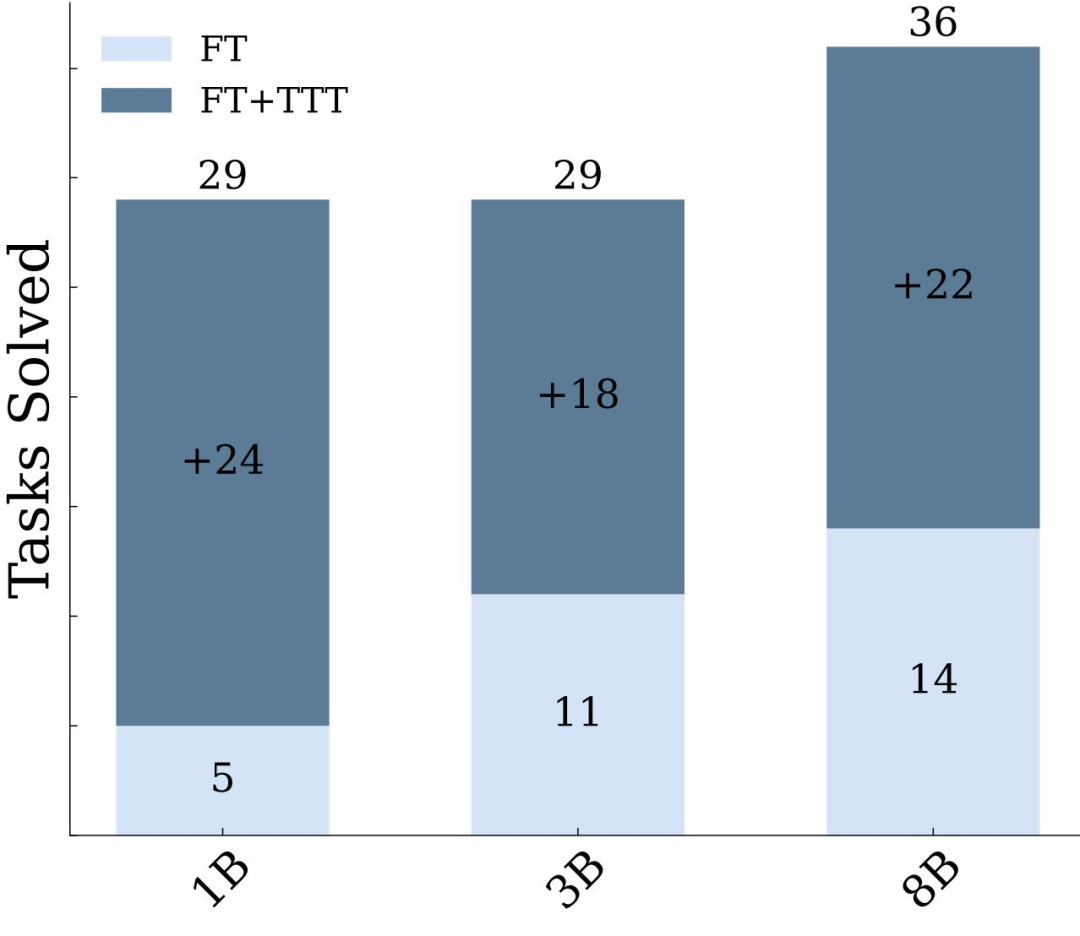
在1B模型中,经过巧妙运用TTT技术,ARC上的准确率大幅提升至原先的六倍,这一数字本身就足以证明其效果。当采用8B模型时,其在ARC语料库上的准确率更是超越了众多已发布的顶尖纯神经模型。原本可能表现不佳的模型,在应用TTT后仿佛获得了超能力。虽然一些神经-符号方法的表现原本尚可,但研究者的研究发现,通过测试时训练的普通语言模型,其性能不仅能与它们相匹敌,甚至还有可能超越。这表明,若需提升模型性能,测试时训练技术(TTT)不容忽视。
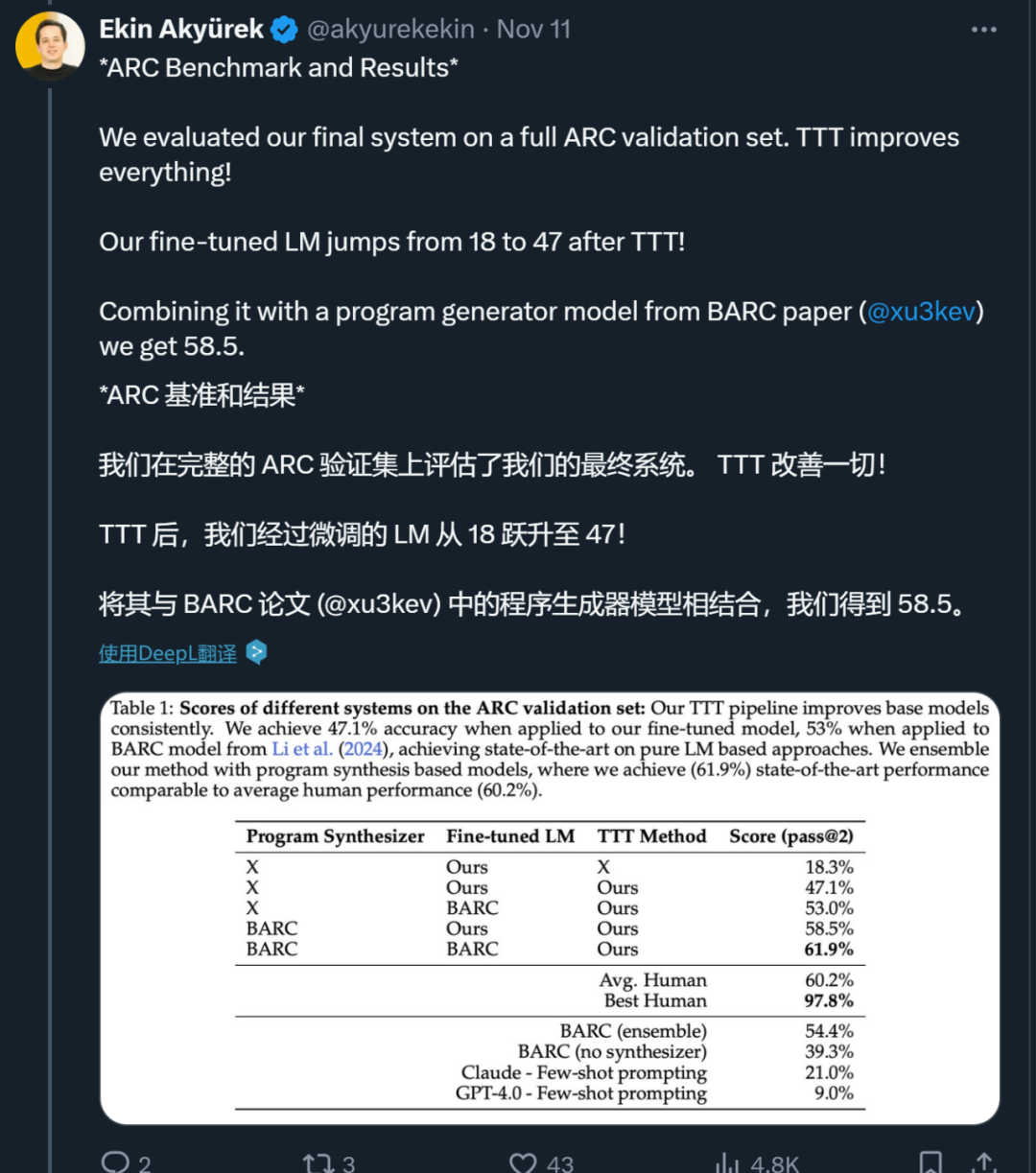
此外,在与其他模型的对比实验中,比如与运用神经和程序合成技术的BARC模型相比,我们的准确率实现了显著提高。过去,BARC的准确率是54.4%,但研究者引入了TTTpipeline后,BARC的微调全神经模型能够处理73.5%的程序合成模型能够解决的问题。这一切都归功于TTT带来的强大效能提升。
TTT设计选择的考量因素

MIT的研究者们发现,TTT的设计选项众多。比如,可以针对每个测试任务单独训练LoRA,也可以利用所有测试任务的数据集来训练一个共同的LoRA。这种选择问题在实验过程中时常出现。实验结果会因选择不同而有所差异。在数据量不大且每个测试任务各有特点的情况下,为每个任务训练LoRA可能更合适;而面对众多相似性较高的测试任务,训练共享的LoRA则可能更高效,同时也能达到较好的效果。

此外,在采用全神经网络方法时,研究者还需考虑使用的是否为预先在文本数据上训练过的语言模型。若决定使用此类模型,必须注意其与项目后续步骤的连贯性。这是因为预训练的语言模型类型,将直接影响到后续TTT技术的效果,以及与系统中其他部分的协同作用。

TTT的完整流程与关键组件
研究者运用全神经网络技术,首先从基于文本数据预训练的LM模型开始。他们在测试阶段,对基础微调模型进行了训练和推理,例如对没有LM数据的8B微调模型。这一过程中,每个环节都至关重要,就好比精密仪器中的每一个小齿轮,缺少任何一个都可能导致整个系统无法正常工作。
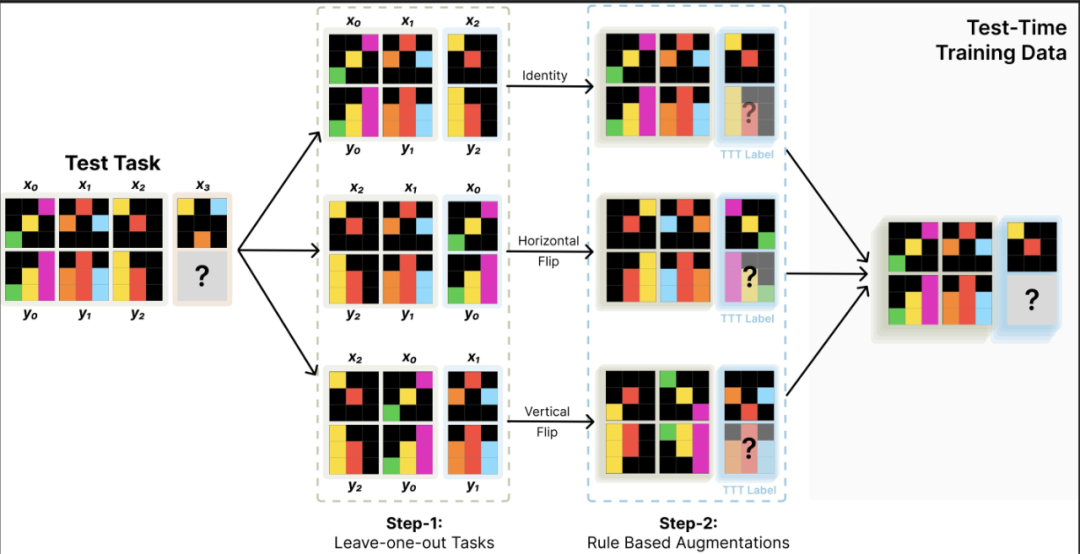
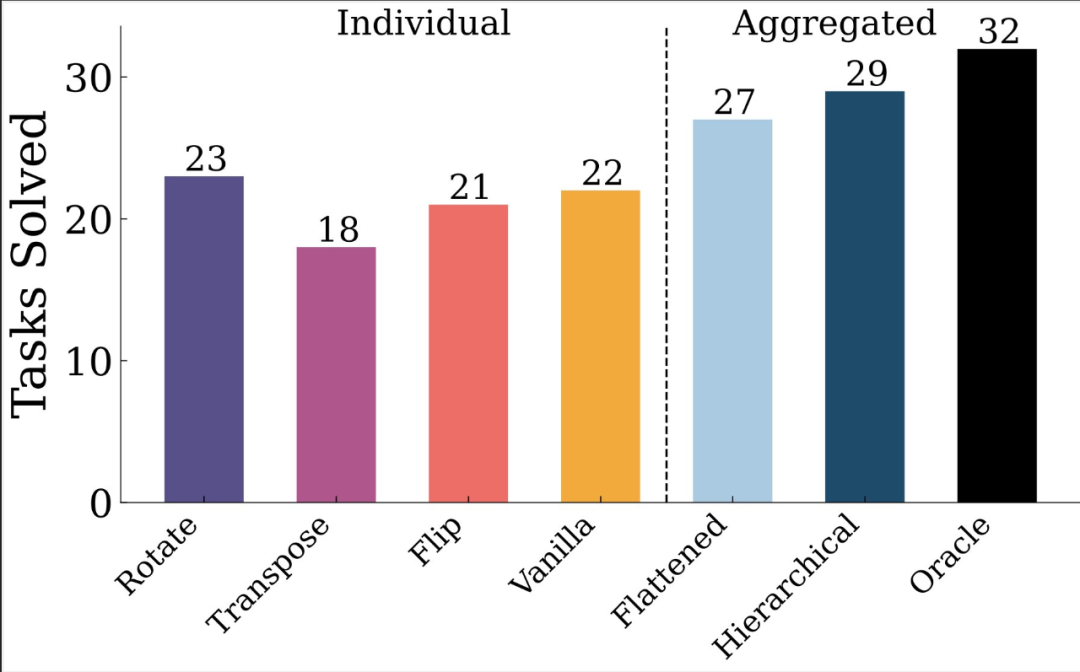
测试环节的训练涵盖了每个任务的LoRA模型以及更庞大的增强数据集。在预测过程中,我们采用了可逆变换下的增强推理技术,并实施了分层self-consistency投票机制。这些关键组件是构建高效能TTT不可或缺的要素,若缺失其中任何一项,都将影响我们达到理想性能提升的目标。
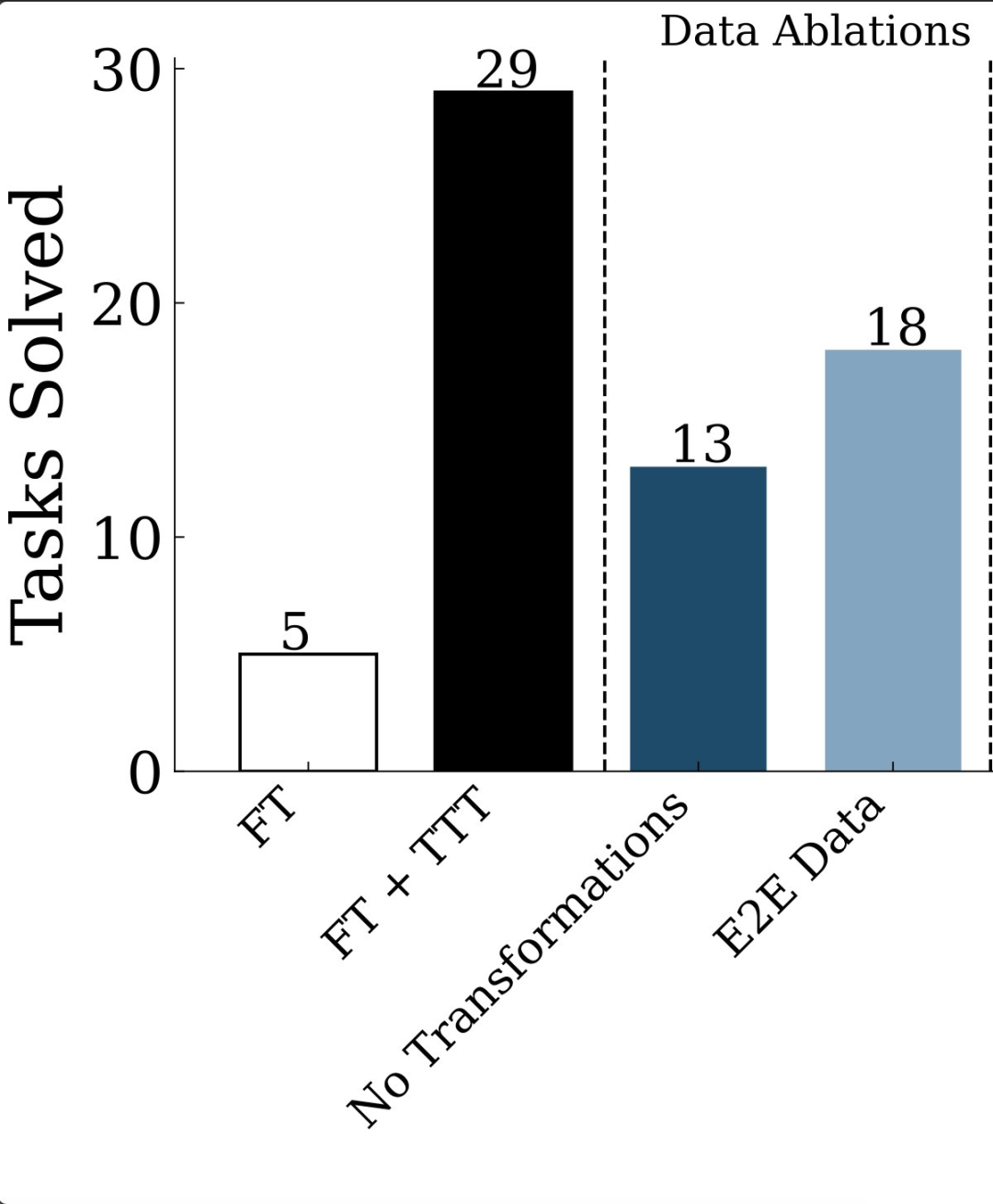
与其他类似方法的比较
最近,一项研究引入了BARC,运用神经与程序合成技术,实现了目前公开报道的最高成绩。然而,本文所采用的TTT及推理流程与BARC存在显著差异。本文的TTT拥有更多辅助组件,旨在提升性能。例如,在BARC基础上增加TTTpipeline后,性能显著提高,这表明即便与较为先进的方法相较,TTT仍具备独特的优势。
在实际的比较中,我们需要从多个维度进行深入分析,这包括但不限于效率的提高、准确率的增强,以及模型对不同类型数据和不同模型适应性的展现。我们不可以仅凭单一角度就断定某一方法就比另一方法更优越。
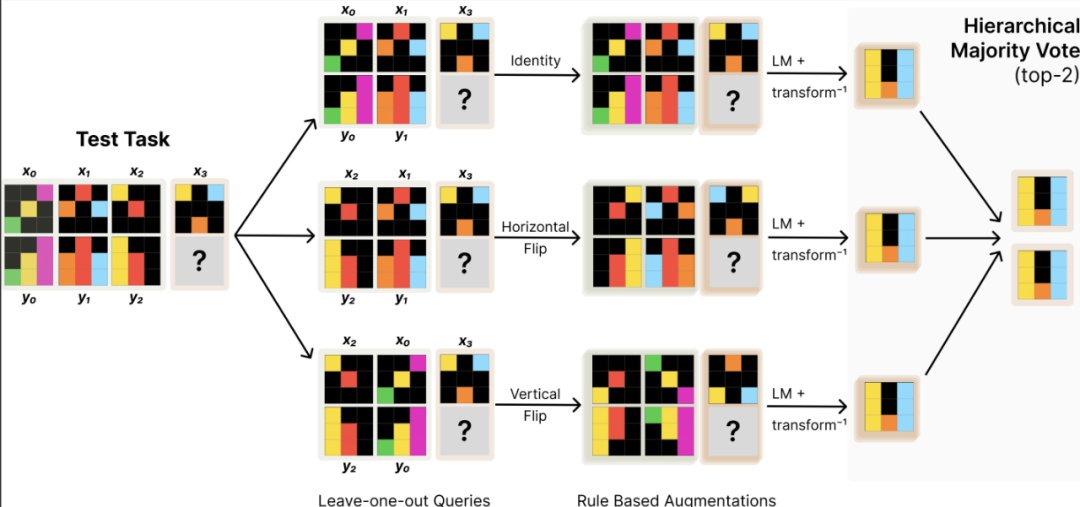
TTT的实际应用前景
TTT在处理如ARC语料库等视觉推理问题时,展现出显著优势。在具体项目中,若需提升模型性能或应对视觉推理等复杂任务,引入TTT是一个可行的选择。然而,实际应用并非毫无章法,需根据项目规模来定。对小项目而言,使用TTT时可能无需过于复杂的配置。
还需注意团队成员对TTT操作掌握的熟练度,若在调整各类参数,比如LoRA的训练方法等环节,缺乏充足的技术人员支持,就应小心使用。
在参与的项目里,你有没有试过使用测试时训练(TTT)来增强模型的表现力?期待你能分享一下你的体验或见解。同时,也欢迎你为这篇文章点赞和转发,让更多的人认识到这一提高模型性能的实用技巧。
内容来自网络,如有侵权,联系删除。

猜你喜欢
发表评论
电子邮件地址不会被公开。 必填项已用*标注
