OpenAI吹哨人Suchir Balaji自杀身亡,生前指控公司侵犯版权
![]() AI工具集
·
浏览 9 ·
点赞 0 ·
评论 0 ·
刚刚
AI工具集
·
浏览 9 ·
点赞 0 ·
评论 0 ·
刚刚
OpenAI 相关的事件持续引发人们的关注,这些事件中工作人员出现了离奇的死亡情况,同时公司还存在版权争议,这两者相互交织,在其背后隐藏着在 AI 发展过程中急需解决的版权问题。

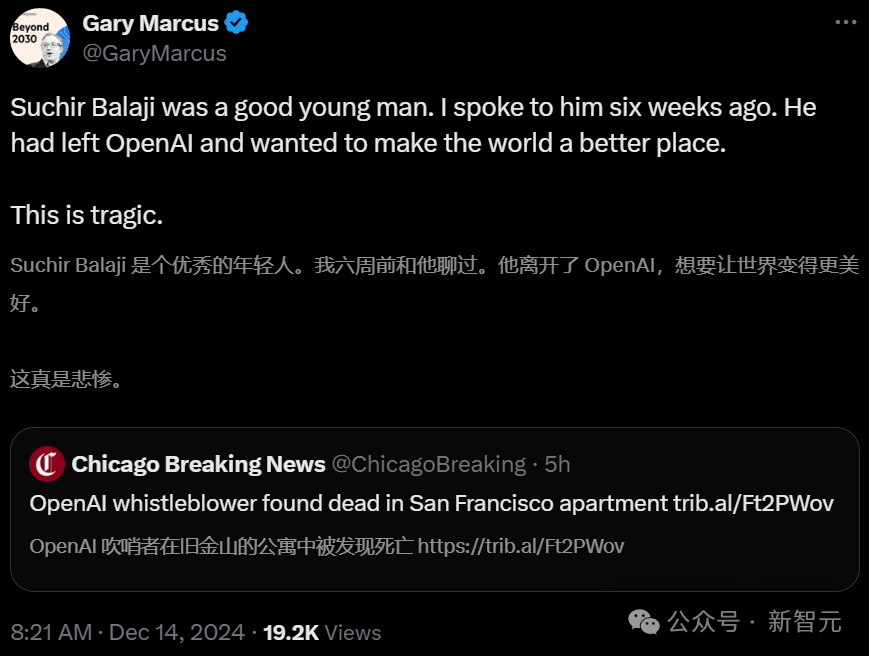
重视数据来源合法性
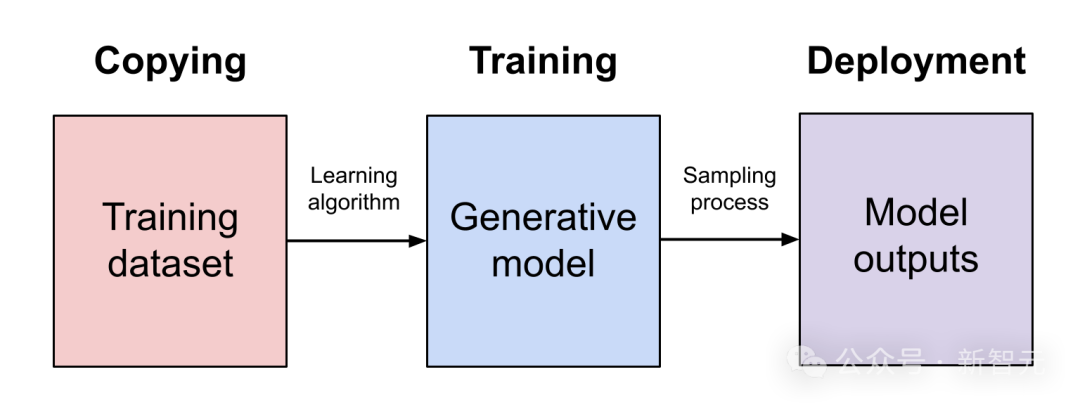
公司在收集数据用于 AI 训练时需重视合法性。例如,OpenAI 被指控利用新闻等网站信息训练 AI 模型,违反了“合理使用”原则,这里涉及诸多法律界限问题。像 OpenAI 收集互联网数据用于 GPT – 4 训练,其范围几乎涵盖所有英语文本,若未经合法授权,就存在侵权隐患。同时,其他 AI 产品在数据收集时要明确来源,即便部分网页未标明禁止采集数据,企业也不能随意使用。

在商业运营方面,许多公司会利用网络数据来构建自身的业务模型。倘若这些数据存在版权方面的争议,那么后续很可能会遭遇极大的法律风险,同时也会带来经济上的损失。很多 AI 公司都急于推出产品,然而却忽视了对数据合法性的审查,这很可能会给未来的发展埋下隐患。

员工的潜在风险
处于 AI 企业的数据收集岗位是有风险的。曾在 OpenAI 工作的 Balaji 卷入了这场版权风波。他被安排收集互联网数据的任务后,察觉到公司的行为可能构成侵权,这给其职业生涯乃至生命安全都带来了风险。有些员工或许因为担心遭到报复等原因,不敢说出公司潜在的违法问题。实际上,员工应该学会保护自己,在就业之前了解公司的数据使用政策,企业也不应该对有疑虑或者持反对意见的员工进行压制。
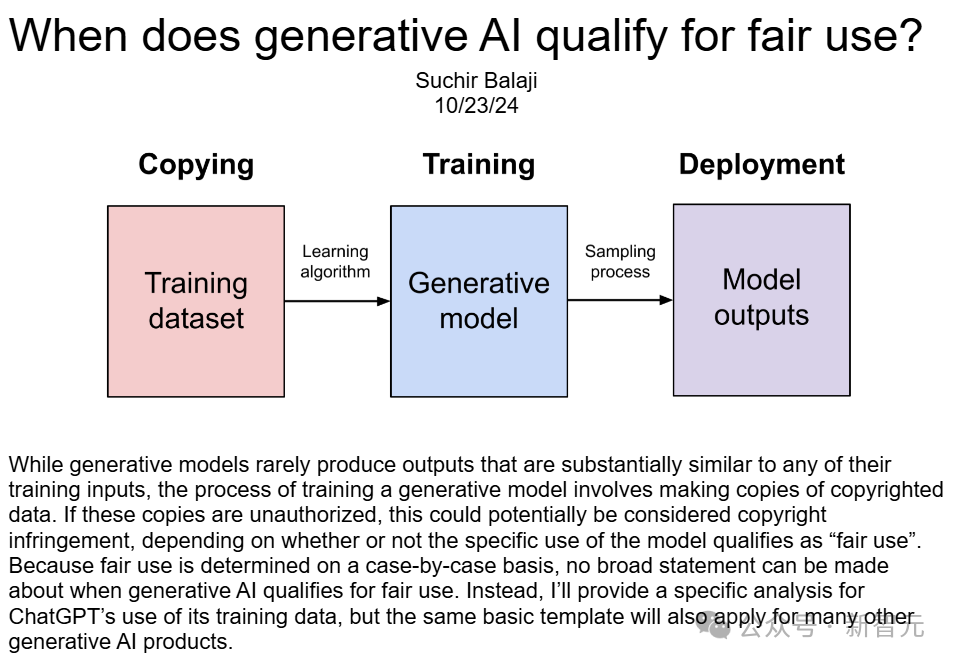
如果员工察觉到公司违法利用数据进行 AI 训练等行为,那么就应该存在举报的渠道。同时,政府以及相关的行业协会也应当构建起针对员工的保护机制。就如同一些企业的员工在发现污染问题后敢于进行举报一样,这需要有相关的组织为其提供安全保障,并且对举报的事件进行调查和处理。
法律界限模糊地带
目前对于 AI 训练数据使用的“合理使用”原则的认定较为模糊。有观点指出,OpenAI 使用受版权保护的材料来训练 AI 是违反规定的,但该公司却认为自己是在合理使用。像《纽约时报》等媒体认为,该公司抄袭盗用文章,损害了其商业模式,然而,并没有确凿的答案能够说明 GPT 训练是否真的构成侵权。许多生成式 AI 产品都面临着类似的困扰,因为并没有明确清晰的标准。

法院审理这类案件时,常常缺乏相关的法律细则作为依据。在司法实践里,可能会遇到新的情况而无法依据法律来处理。例如,用传统的版权观念来衡量 AI 训练中的数据使用情况时,就会面临困难。这就需要法律部门加快立法进程,或者出台一些解释性的文件。


对行业的连锁反应
OpenAI 的版权问题给整个行业的商业模式带来了冲击。新闻机构认为自身文章被抄袭盗用,导致其商业模式受到损害。并且从数据许可市场来看,若 AI 训练未经授权就使用受版权保护的数据,将会剥夺版权持有者的合法收入来源。例如,GPT 发布后,Stack Overflow 的访问量下降,新用户减少,这表明了相似业务模式正遭受威胁。
这要求整个行业对业务发展与版权保护的平衡进行重新思考。不能只专注于追求 AI 的智能程度,而将数据来源的正当性忽视掉。不同的商业模式之间存在着相互连通、相互影响的效应,一个主体的侵权行为容易致使整个商业生态的平衡被打破。

证据收集的难点
在这类 AI 版权侵权诉讼里,证据收集存在困难。就像《纽约时报》对 OpenAI 提起的诉讼那样,Balaji 掌握着“独特的相关文件”,然而这样的员工数量很少。要明白,OpenAI 的训练集并未公开,要是想要证明其侵权,就很难确定其训练数据的来源是否非法。并且,对于有多少数据来源属于侵权,这是很难进行量化的。
需要构建起有效的证据收集以及保存机制。在互联网大数据的时代,众多数据会很快消失不见。要是没有有效的证据保存手段,一旦涉及诉讼,就会处于不利的境地。例如,某些电子证据可能会轻易地被删除或者被篡改,因此确保证据的有效性是极为重要的。
对整个AI发展的警示
这一系列事件给 AI 的长远与健康发展敲响了警钟。AI 取得进步不能用侵犯版权来换取。当下 AI 的训练数据使用必须遵守法律法规,技术创新与法律规范应同等重视。例如在 AI 图像生成领域会遭遇数据版权方面的问题,过度依赖未获授权的数据进行训练,对整个 AI 产业的发展以及社会的接受度都不利。
各位读者,你们觉得在当下的这种局势当中,AI 企业怎样才能够迅速地对自身数据来源的合法性进行自查?倘若你认可本文,欢迎进行点赞以及分享。
内容来自网络,如有侵权,联系删除。

猜你喜欢

发表评论
电子邮件地址不会被公开。 必填项已用*标注
