法国开源大模型 Pixtral Large 超 GPT-4o,成最强开源多模态模型
![]() AI工具集
·
浏览 192 ·
点赞 0 ·
评论 0 ·
4个月前 (11-22)
AI工具集
·
浏览 192 ·
点赞 0 ·
评论 0 ·
4个月前 (11-22)
PixtralLarge的参数规模宏大,多模态功能亦十分突出。LeChat利用它展现出了许多独到之处。这其中包含了大量对用户极具价值的信息,无论是技术专家还是普通创意人士,都能从中获得益处。
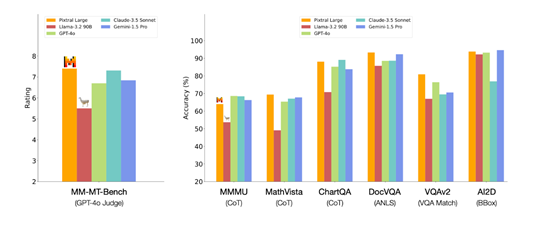
理解PixtralLarge参数量的意义
参数的多少常常影响着模型的能力。以PixtralLarge为例,它拥有1240亿个参数,如此庞大的参数量使得它在处理信息时占据优势。比如,在处理长文本中的语义关系时,它能够捕捉到细微的逻辑联系。在一个文本翻译项目中,这样的模型能更深入地理解源语言的复杂语义,并将其准确转换为目标语言。此外,它还具备128K的上下文窗口,这使得它能够处理大量的文本数据,无需频繁分割文本。
同时,多模态能力与参数的强大结合,使得它能够高效地处理图像与文本数据。举例来说,在图像标注项目中,它能够精确地识别图像中的物体,并提供与场景相符的文本描述。
多模态解码器的核心作用
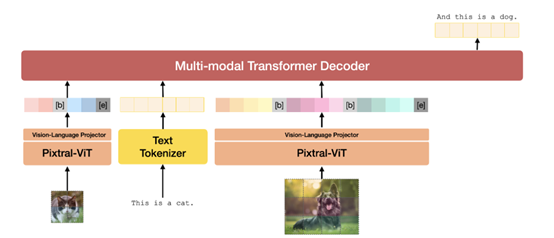
PixtralLarge的核心是多模态解码器。这个解码器的主要职责是融合视觉编码器的信息和文本数据。这个过程虽然复杂,但效率很高。以视觉问答为例,它需要处理图像中的视觉关系和文本中的问题。为了完成如生成精确图像描述这类高质量任务,多模态解码器会运用1230亿参数来处理不同模态数据间的联系。
在处理涉及图像与文本的文档理解工作时,多模态解码器能够精确地识别图像与文字之间的联系。它能识别出文件中的插图,判断其是否是对特定文字的补充说明,而非无关紧要的元素。
视觉编码器的关键功能
视觉编码器在参数量达到10亿时至关重要。它能将图像转化为高维特征表示,这是模型理解图像的基础。比如,在分析风景照片时,视觉编码器会将照片中的颜色、形状等元素转化为模型能够理解的特性。此外,它还运用了自注意力机制。以分析人群照片为例,模型能够考虑到整个画面中的人物关系和场景布局等全局上下文。
这一机制使得模型能够把握图像与文本数据之间的互动关系。在处理艺术作品的文字说明时,模型能够领悟文字所蕴含的艺术风格与图像内容之间的相辅相成。
序列打包技术的好处
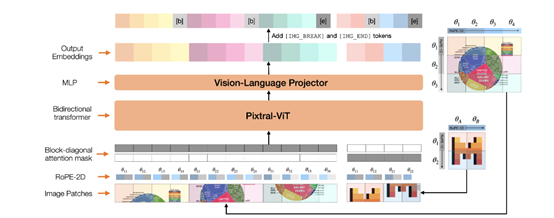
序列打包技术新颖,能有效提升模型运作效率。该技术通过构建块对角掩码,确保图像间的特征互不干扰。在批量处理图像时,例如相册中的多张照片,它能精确分离每张照片的信息,同时不消耗过多计算资源。
在处理多图像数据时,无论是用于图像分类还是图像创作,都能更高效、更准确地得到结果。
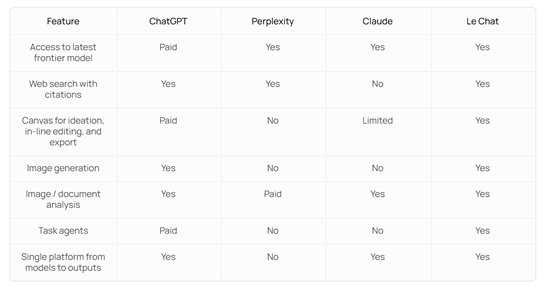
LeChat的特色功能
LeChat的Canvas功能对创意工作大有裨益。若是广告创意团队,成员便能在Canvas上展开头脑风暴,随意构思广告创意并进行内容编辑。而且,导出格式灵活多样,无论是线上展示的电子文档,还是线下印刷的高分辨率图片,都能轻松实现。

FluxPro这款图像生成技术非常便捷,用户在LeChat中就能轻松制作出高质量的图像。制作海报时,无需切换至其他图像编辑工具,即可直接生成所需的海报元素。
共享Agent的工作流管理
将工作流程转化为Agent并共同使用,效率颇高。在项目团队里,成员们能够根据各自团队的任务特性,比如市场调研团队的信息搜集与分析流程,将其转换成Agent。这样,团队成员就能轻松共享这一流程,并实现自动化操作,从而提升整体工作效率。此外,LeChat提供的从模型到输出的全集成平台,使得用户仅需在一个平台上工作,例如,多模态内容创作者无需在文本创作平台和图像编辑平台之间切换,即可完成所有创作任务。
你明白怎样运用这些功能来最大限度地提高你的工作效率和创作效率吗?期待你能为这篇文章点赞、转发,并在评论区分享你的见解。
内容来自网络,如有侵权,联系删除。

猜你喜欢
发表评论
电子邮件地址不会被公开。 必填项已用*标注
