揭秘AI对话背后的本质:从数据标注员到AGI的进化之路
![]() AI工具集
·
浏览 13 ·
点赞 0 ·
评论 0 ·
2天前
AI工具集
·
浏览 13 ·
点赞 0 ·
评论 0 ·
2天前
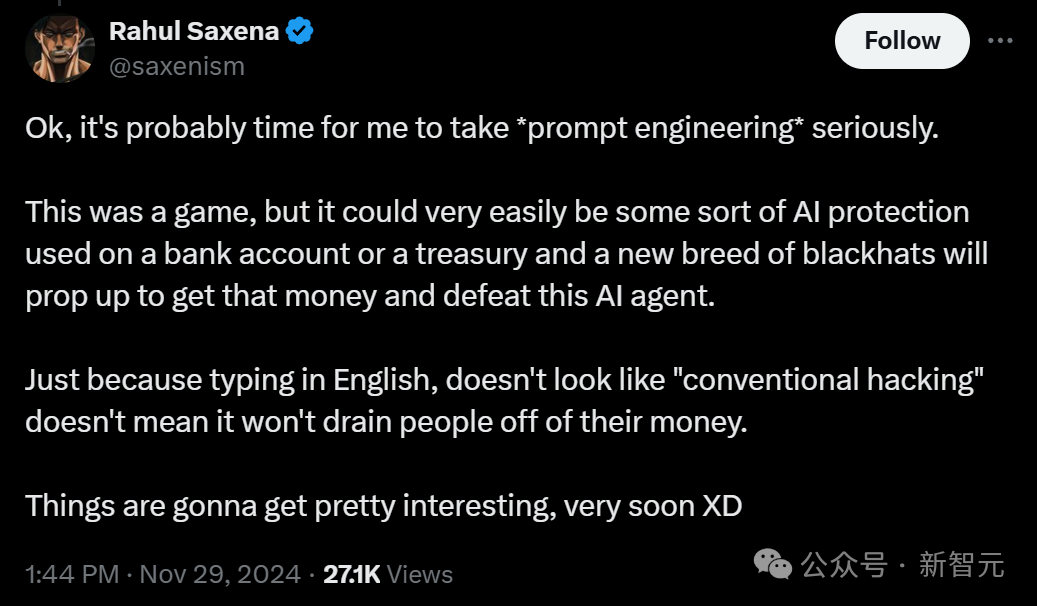
在科技讨论中,AI经常被提及。很多人对向AI提问的想法抱有憧憬,觉得AI仿佛无所不能。但真相是,它的运作离不开数据标注员的工作。这种理解上的差距,正是我们应当重视的问题。
正视向AI提问的本质

很多人认为向AI提问就如同向一位超级智者咨询。然而,实际上,我们是在向那些负责数据标注的人类专家提问。比如,在某些对话场合,AI似乎给出了巧妙回答,但实际上,这些回答背后是众多数据标注员的知识和经验累积,这些内容最终转化为大语言模型中的token序列。我们不应过分崇拜AI,认识到这一点,有助于我们更加理智地看待AI在生活中的作用。此外,我们还应了解,这些标注员是通过在微调数据集中挑选地点类型的统计特征来制定答案模式,在使用AI时,我们不应忽视这一背后的逻辑。
RLHF的真实情况
RLHF常被误读。以前有人批评它勉强算强化学习,而“真正的强化学习”在奖励函数难以设定的领域应用不易。现在RLHF只是依托人类反馈的强化学习,并非超凡脱俗。比如在数学领域,尽管有了RLHF的辅助,但受限于底层模型的知识广度和推理能力,LLM并不能在所有数学问题上都表现得很好。在使用含有RLHF技术的AI产品时,我们需明确其能力范围。此外,也要认识到,它目前的研究阶段还有许多缺陷,并非完美无瑕。

ScalingLaw的含义

ScalingLaw阐述了模型输入与输出的联系,这影响着模型效能。然而,多数ScalingLaw研究的是模型预测下一个词的能力,这与实际任务的表现有所差异。比如,Kaplan等人、Chinchilla和Llama的研究,它们预测的能力并不完全等同于实际任务中的表现。在具体应用中,我们不能仅凭ScalingLaw来评价模型在现实任务中的表现,这一点至关重要,以防对AI能力产生错误判断。另外,若对ScalingLaw理解有误,可能会在众多项目中造成不切实际的预期,进而影响与AI相关的决策和战略布局。

现实任务性能预测的挑战
在现实任务中,预测模型的表现不易评估。据2023年JasonWei在博客中提到,目前尚不明朗替代指标能否准确预测能力涌现。将上游损失与实际任务性能进行定量关联相当不易,毕竟相关研究尚处初期,数据点稀少使得选择拟合函数显得主观。以某些研发场景为例,若要预测新开发的AI功能在实际应用中的表现,往往缺少准确的预测依据。即便存在一些初步的预测方法,其结果也可能大相径庭,因为目前缺乏足够的数据来支持精准预测,研发者易陷入误区。
改进预测的方向

提升模型在真实场景中的预测能力有多种方法。比如,采用更精准的缩放定律,这相当于为迷失方向的人提供了一张更精确的地图。比如,研究更贴近实际的定量关系,或者利用更优质的数据和计算方法。在优化AI模型的过程中,若能准确把握这些提升预测精度的手段,就能让AI在实际应用中展现出更佳的性能。然而,当前的研究进展并不理想,因为新型模型架构和数据组合的持续演变,使得下一代模型的缩放定律可能有所不同,目前还难以实现精确的改进。

准确评估AI模型的必要性
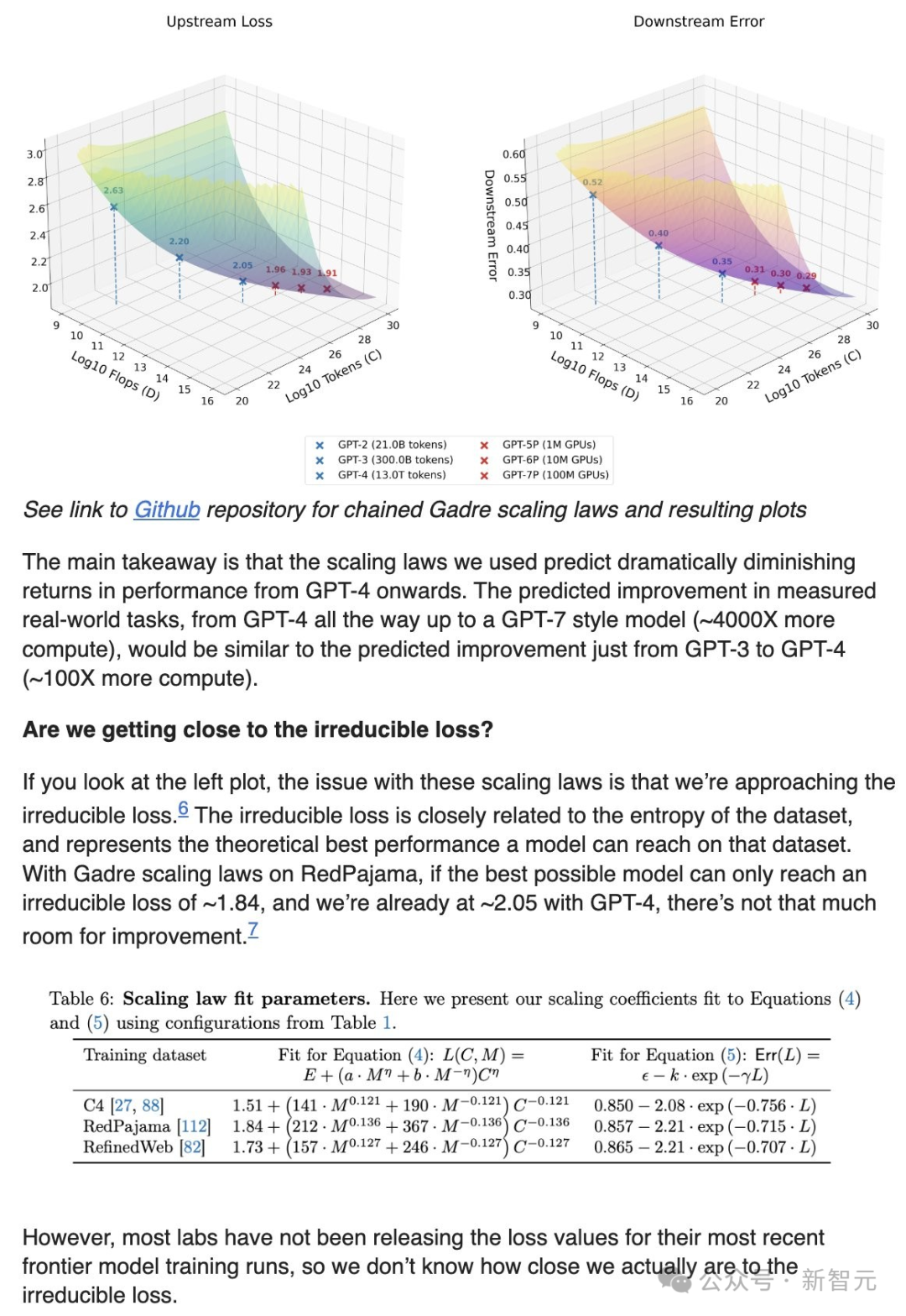
要准确判断现在的AI模型是否还能进行扩展,我们需要更多有根据的预测和更完善的评估标准。随着每一代AI模型的进步,缺乏准确的评估方法就像盲人摸象一样。以AI科技公司为例,若缺乏有效的评估,盲目投入资源进行扩展,可能只会徒劳无功。在这个科技飞速发展的领域,准确的评估有助于把握技术趋势,更充分地挖掘AI的潜能。
亲爱的读者,在与AI交流时,你是否察觉到了背后人员的辛勤付出?欢迎留言交流。同时,也请为我们点赞并转发这篇文章。

内容来自网络,如有侵权,联系删除。

猜你喜欢

发表评论
电子邮件地址不会被公开。 必填项已用*标注
