OpenAI 分享前沿模型安全测试方法,AI 与人类协作提升安全性和效率
![]() AI工具集
·
浏览 7 ·
点赞 0 ·
评论 0 ·
刚刚
AI工具集
·
浏览 7 ·
点赞 0 ·
评论 0 ·
刚刚
在科技迅猛发展的今天,AI的安全问题引起了广泛关注。它就像一座高楼,若根基不稳,后续发展可能随时面临崩溃的风险。因此,OpenAI聘请外部红队人员和进行自动化安全测试,背后有着极其重要的意义。
组建合适的红队成员
挑选具备专业资质的员工十分关键。不同领域如网络安全、自然语言处理、机器学习的专家,他们的知识有助于从多角度审视问题。以测试自然语言处理的AI为例,自然语言处理专家能迅速发现逻辑上的缺陷。此外,OpenAI在选拔时注重不同专长的人才,以便在复杂多变的风险环境中进行测试。在2022年的某次AI模型测试中,由于缺乏自然语言处理专家,导致与语法和语义相关的安全漏洞未能及时被发现。
来自不同背景的成员携手合作,汇聚成强大的力量。在分工合作的过程中,他们能够全面覆盖攻击目标。以网络安全领域为例,网络安全专家注重数据传输和网络架构的安全性,与其它领域的专家紧密协作,从而更有效地从多角度保障人工智能系统的安全。
红队测试的关键步骤
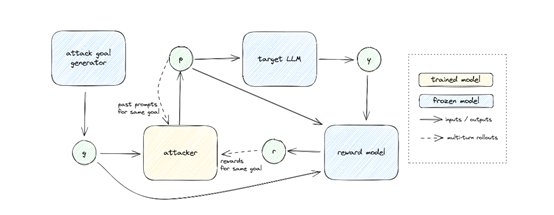
生成多样化攻击目标至关重要。为实现这一目标,需采用多种手段,例如,通过少量样本提示法为模型提供示例,引导其生成新的目标。在一次网络公司的AI测试中,正是运用此法,迅速发现了之前未曾检测到的风险点。
有效的攻击生成至关重要,这是后续工作的基础。这依赖于众多专业设计,比如RBRs这类奖励函数的运用。它能够针对特定目标对模型输出进行评估,将攻击的成功与否以及达成程度都转化为可量化的指标。以评估有害内容生成为例,RBRs能够精确地判断模型输出中是否存在有害信息。
RBRs的评估标准设计
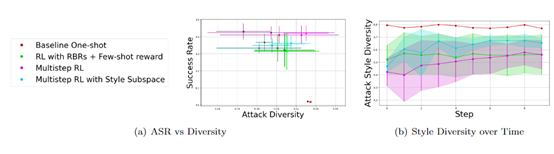
攻击目标转化为评估标准至关重要。将攻击目标用作提示信息输入大模型,制定评估标准需力求精确。以AI系统中的隐私数据泄露风险为例,所设定的评估标准需聚焦于数据访问权限等核心要素。
精确分类确保了评估的准确性。大模型在处理生成文本时,会根据既定标准进行分类,以判断其是否符合要求。因此,RBRs的设计必须既精确又全面,否则可能会忽视某些高风险情形。在一次评估中,由于RBRs的设计存在缺陷,一些潜在的安全隐患输出未能得到恰当的标注。

测试结果的详细记录
详尽记录对评估风险至关重要。需记录提示、文本生成、风险种类及其严重性,还有改进的建议。这样做便于追踪测试过程,方便日后查阅相关数据。比如,若记录显示某次测试导致AI未能妥善保护用户信息安全,改进建议就能有针对性地提出。
记录方式需与模型进步同步。AI模型不断升级,例如多轮对话和多模态交互的进步,这要求记录方式能够捕捉到新的风险数据。在2023年对一款多模态交互AI的测试中,正是通过更新记录方式,我们才得以完整收集到这些新的风险数据。
数据合成和政策比对
将测试数据与现行政策进行对比。红队的数据必须与政策进行核对,以保证不违背相关原则。这涉及到保护用户隐私、遵循法律法规等多方面的政策要求。曾有一款AI产品在海外拓展时,由于对当地政策不熟悉,未进行充分的数据比对,几乎遭遇了严重的法律风险。
需对示例进行违规性评估。对红队测试生成的示例进行细致分析,从中挑选出那些符合以及违背政策规定的案例。此举有助于为模型的优化工作打下基础,并确保模型能够朝着合法、合规且安全的方向不断进步。
改进模型的后续发展
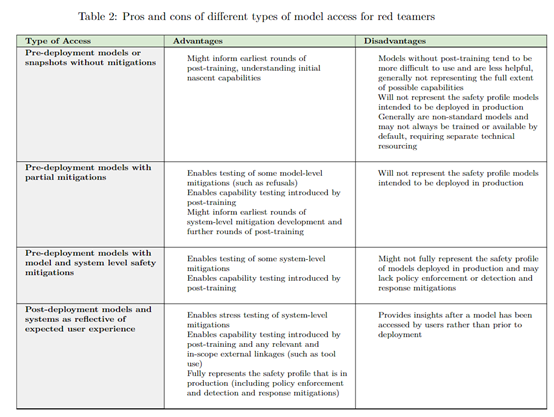
分析测试结果至关重要。OpenAI在测试结束后进行了深入分析,并将所得建议应用于模型的后续训练与优化。这整个过程是一个持续的迭代。在确保模型安全的过程中,我们无法一蹴而就,每一次的测试总结都成为了提升安全性能的台阶。
提升模型的鲁棒与安全性能。经过上述步骤,我们旨在确保模型在各种环境下都能稳定运作,并确保其安全性。只有这样,模型在实际应用中才能避免出现不可挽回的风险问题。
你对AI安全评估的细节是否感兴趣?或者你有相关经验?不妨在评论区留言分享。此外,点赞并转发这篇文章,能让更多人得知这些关键信息。
内容来自网络,如有侵权,联系删除。

猜你喜欢



发表评论
电子邮件地址不会被公开。 必填项已用*标注
